Hello HoloViz Community!
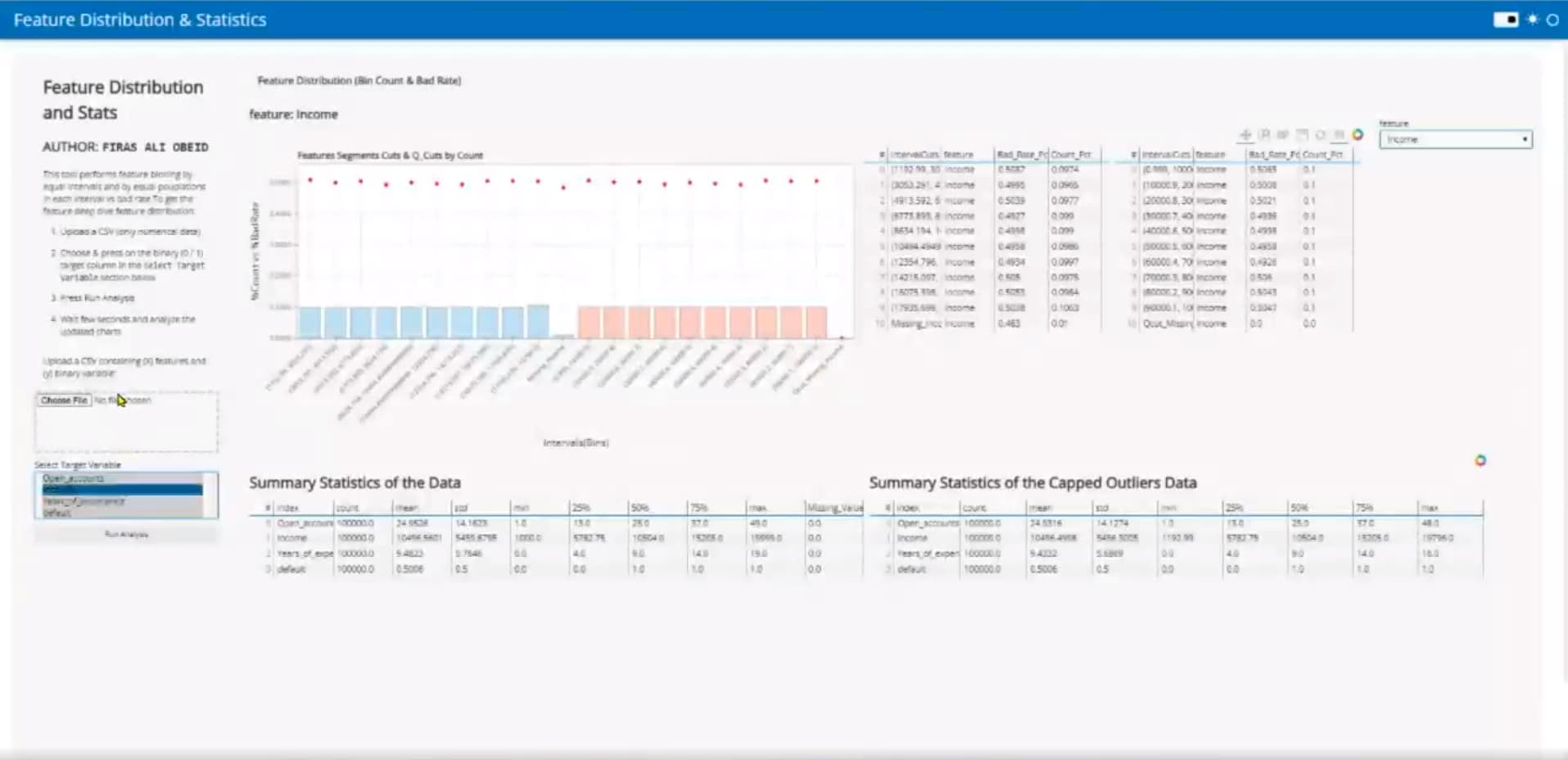
I have developed and deployed a credit risk data science tool for feature (variables) distribution analyzing per the target variable (the variable that is in scope of the prediction task). Whilst, I am open sourcing with a GitHub license. The tool runs anywhere when you open the site in the browser and installs python instantaneously their in runtime. The tool takes in a csv and the user must choose what is the target variable (i.e default/not, give credit card/no, and other binary prediction tasks) before the analysis is performed using heavy panda’s aggregations and advanced python visualizations.
Please find the deployed app: Deployed App