Hi @chrisj
I finally could make it work in AWS ELB with Docker. I needed 3 files: application.py, Dockerfile, and requirements.txt. As previously said, the bokeh server is not WSGI, so it can not be deployed as a single py file like the dash example. The docker container is needed for the websocket used by bokeh can work.
application.py
import numpy as np
import pandas as pd
import panel as pn
import hvplot.pandas
measure_selector = pn.widgets.Select(name='station', options=[
'random_numbers_1', 'random_numbers_2', 'random_numbers_3'], value='random_numbers_1')
# use to generate dummy dataset into file
data = np.random.randint(5, 3000, size=(100000, 3))
df = pd.DataFrame(
data, columns=['random_numbers_1', 'random_numbers_2', 'random_numbers_3'])
df.index.name = 'idx'
df.to_csv(r'random_numbers_1.csv')
df.to_csv(r'random_numbers_2.csv')
df.to_csv(r'random_numbers_3.csv')
def create_plot(measure_name):
print('update plot for', measure_selector.value)
df = pd.read_csv(measure_name+'.csv')
return df.hvplot.line(
x='idx', y=measure_name, label=measure_name,
width=1500, height=800).opts(tools=['hover'])
layout = pn.Column(pn.Column(measure_selector),
create_plot('random_numbers_1'))
def update(event):
print('field', measure_selector.value)
layout[1].object = create_plot(measure_selector.value)
measure_selector.param.watch(update, 'value')
layout.servable()
Dockerfile
FROM continuumio/miniconda3
EXPOSE 5006
EXPOSE 80
COPY requirements.txt .
RUN pip install -r requirements.txt
COPY application.py .
CMD panel serve --show \
--allow-websocket-origin="*" \
application.py
requirements.txt
numpy
panel
pandas
hvplot
The steps I followed were:
-
Install the aws eb CLI (Install the EB CLI - AWS Elastic Beanstalk)
-
Execute eb init and apply default values.
-
Execute eb create and apply default values.
-
Execute git add .
-
Execute git commit -m "commit files"
-
Execute eb deploy
I read in several places that in and out rules need to be defined in port 80 and 5006 and tried them (Configure security groups for your Classic Load Balancer - Elastic Load Balancing), but I think they were finally not used.
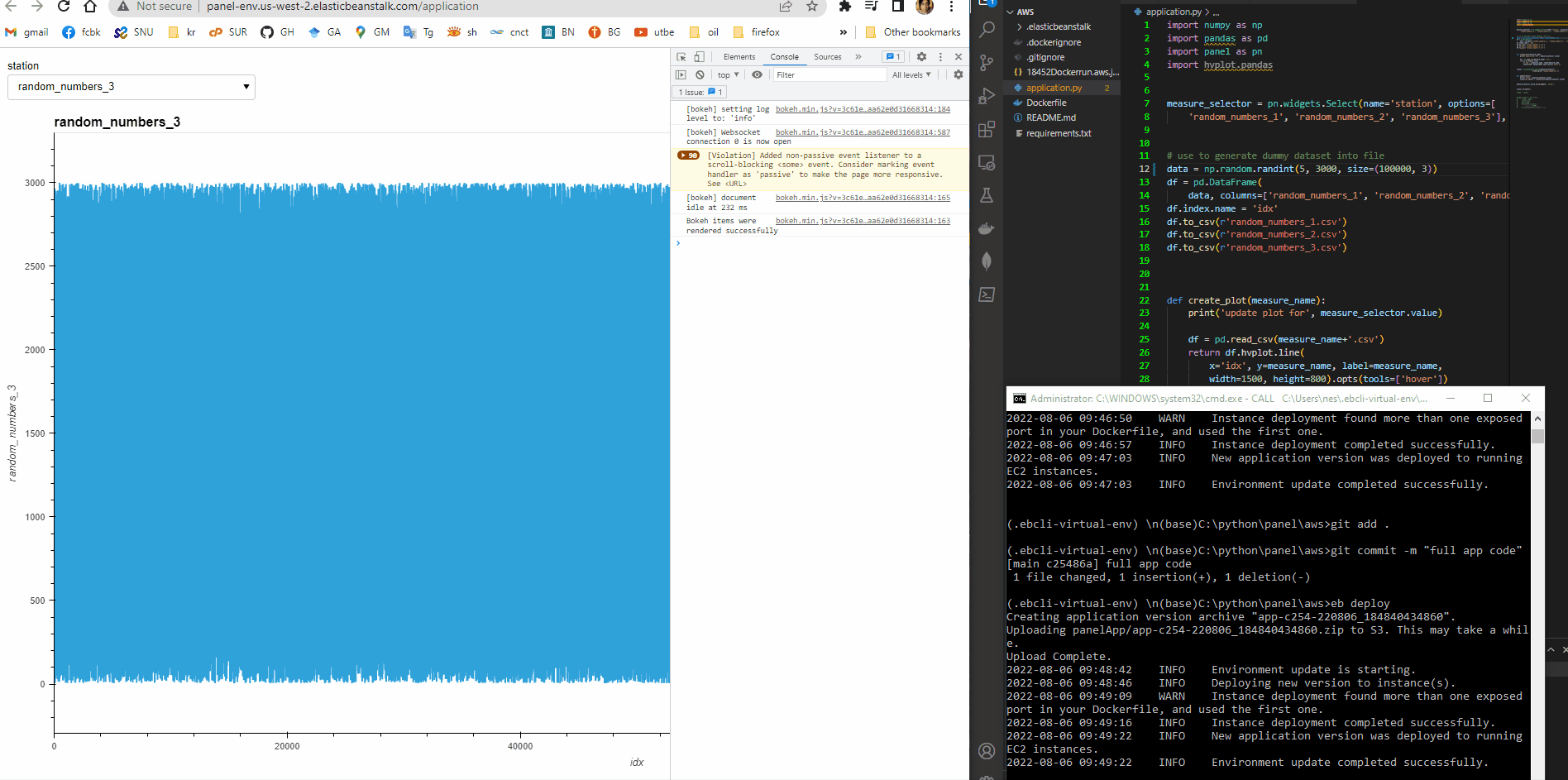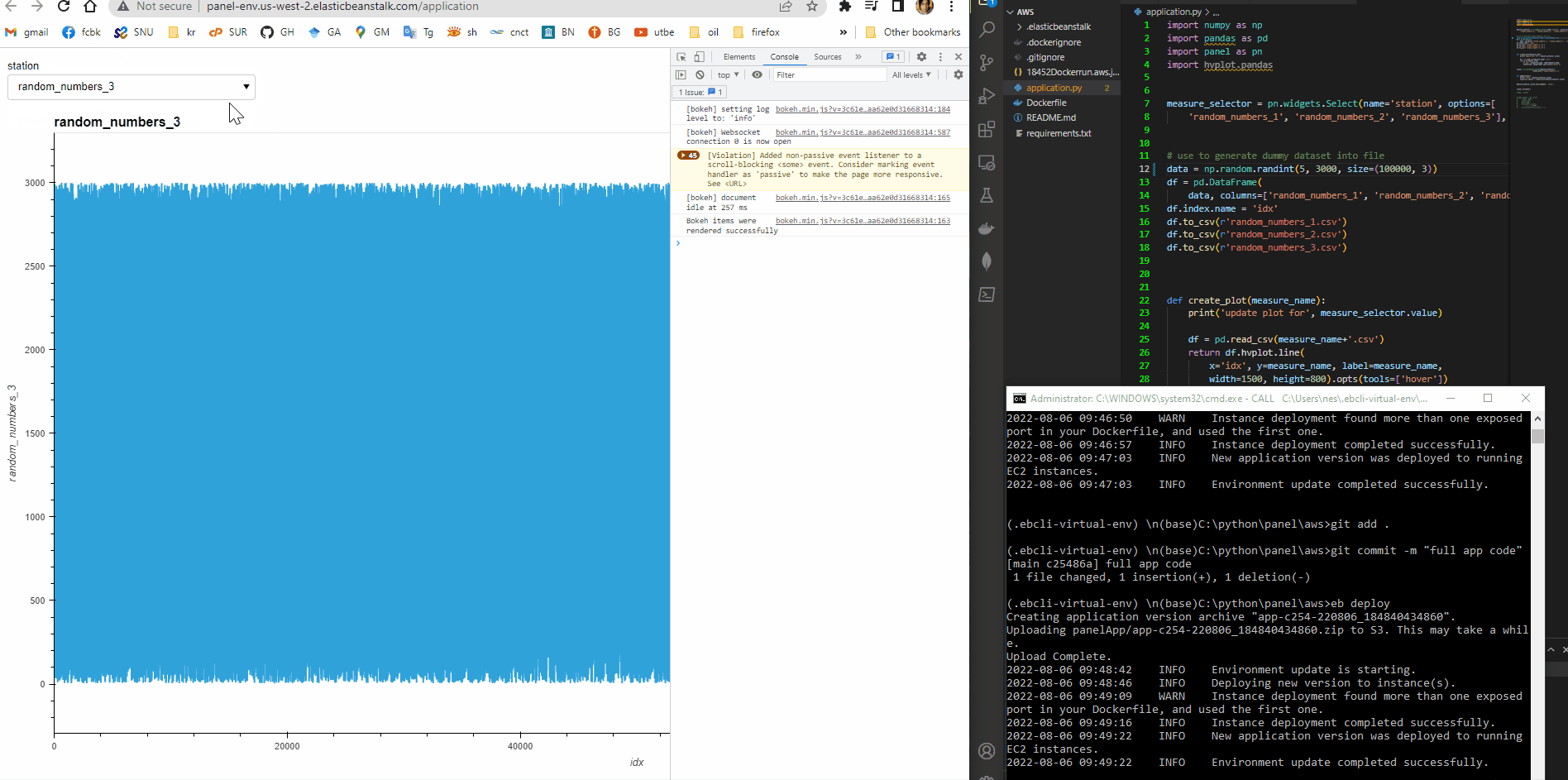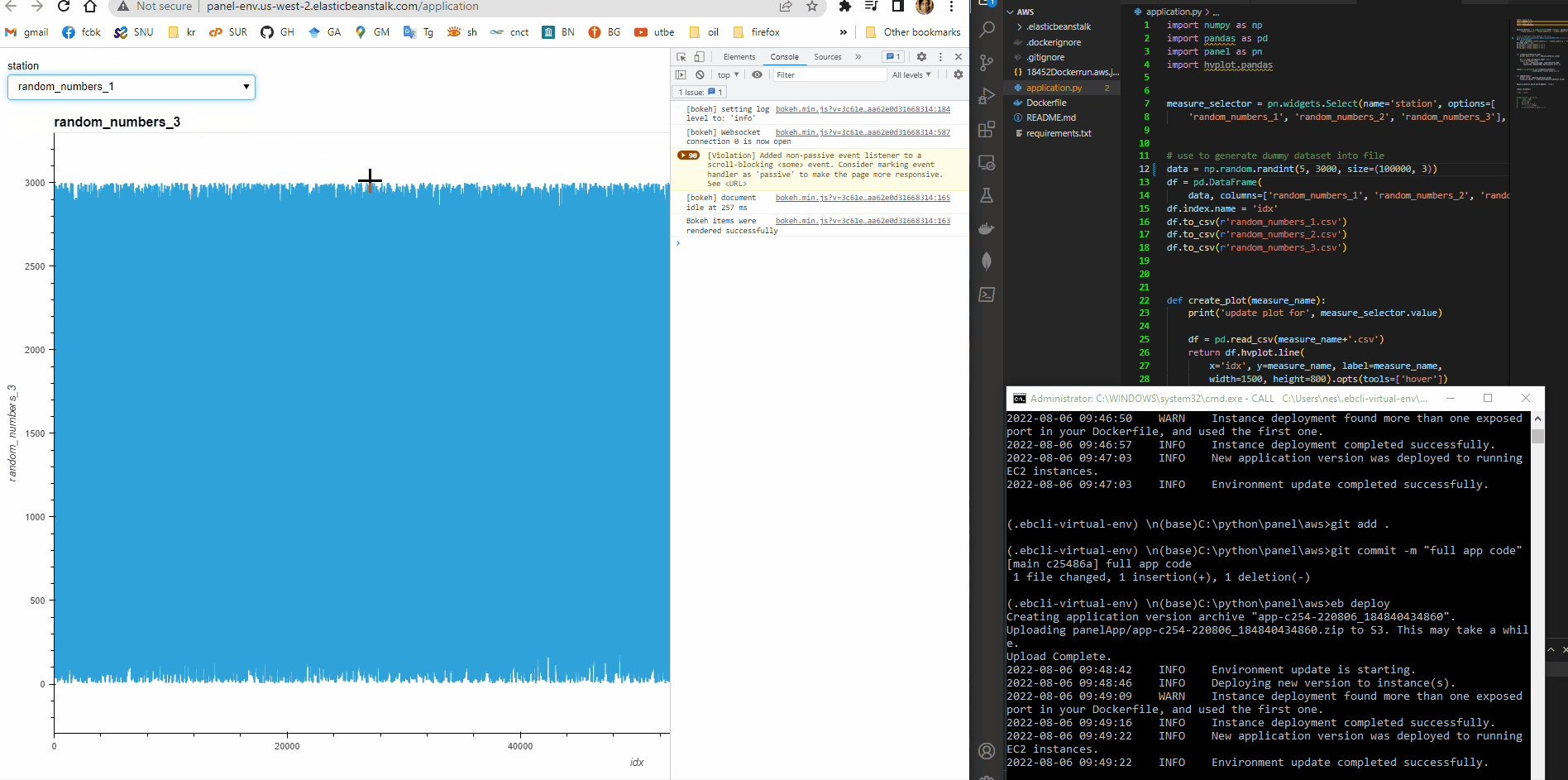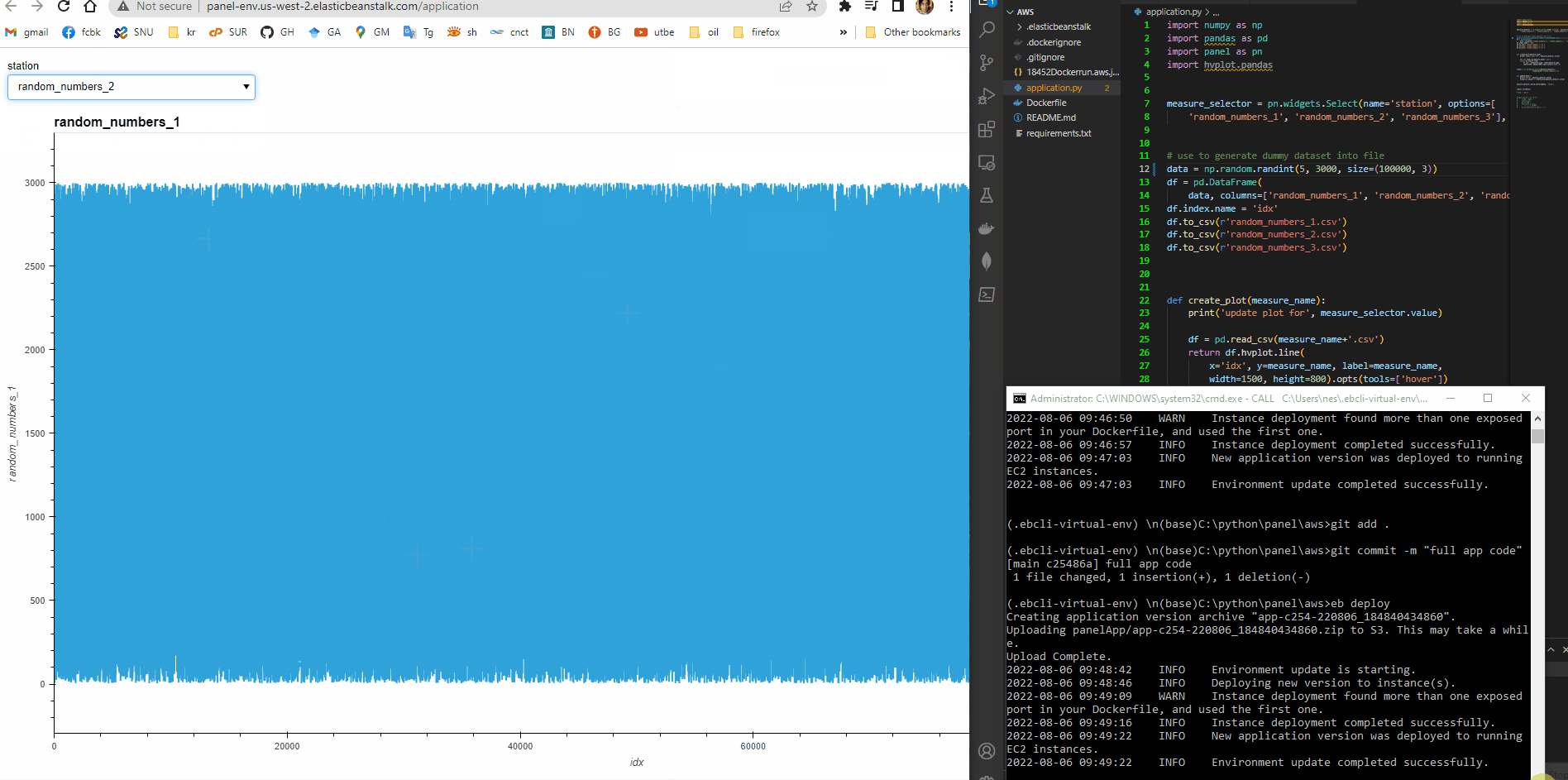
Additional info: As you can see in the video, the app is something slow. It would be worthwhile to check the ```pn.state.cache`` option to load the data faster (Panel Performance larger Files). Another thing that can improve the time response is to try Datashader (https://datashader.org/), due bokeh can not handle big data optimally. Other options would be sub-sampling the data or using Plotly with a novel package called plotly-resampler (GitHub - predict-idlab/plotly-resampler: Visualize large time series data with plotly.py). It is not clear which solution is better, so you need to give them a try to see which adapts better to your requirements.