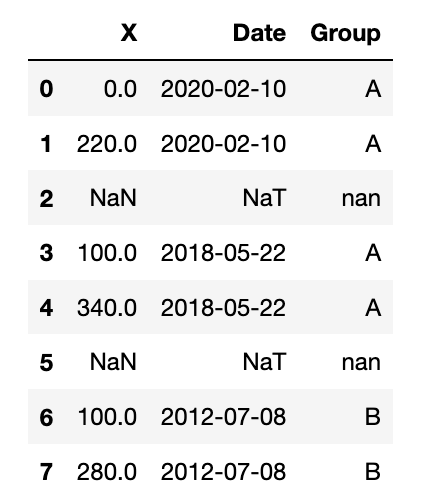
Hello everybody! I wanted to ask if someone has a solution for this problem:
I have a hv.NdOverlay plot of multiple holoviews.Curve objects. The Curve objects belong to a group (in this case either group ‘A’ or group ‘B’). How do I set up the hv.NdOverlay plot to show a legend which shows the two groups?
What I tried is to generate a curve_dict and then executing hv.NdOverlay(curve_dict), which did not display the legend I was looking for. Meanwhile, I found a great example here:
https://nbviewer.jupyter.org/github/poplarShift/pyviz-recipes/blob/master/notebooks/styling_by_attribute.ipynb (Option 2). This comes very close to what I’m after. Unfortunately, in my plot, all lines are connected.
Code example (holoviews version: 1.13.5):
import holoviews as hv
import numpy as np
import pandas as pd
from datetime import datetime
from holoviews import opts, dim
hv.extension('bokeh')
x_start = [0, 100, 100, 0, 120, 200]
x_end = [220, 340, 280, 120, 290, 400]
date = [datetime(2020, 2, 10, 0, 0, 0), datetime(2018, 5, 22, 0, 0, 0),
datetime(2012, 7, 8, 0, 0, 0), datetime(1999, 12, 28, 0, 0, 0),
datetime(2004, 3, 21, 0, 0, 0), datetime(1992, 11, 23, 0, 0, 0)]
group = ['A', 'A', 'B', 'A', 'A', 'B']
df = pd.DataFrame({
'X': np.dstack((x_start, x_end)).flatten(),
'Date': np.dstack((np.array(date, dtype='datetime64'), np.array(date, dtype='datetime64'))).flatten(),
'Group': np.dstack((group, group)).flatten()})
curves = hv.Dataset(df, ['X']).to(hv.Curve, 'X', ['Date'], 'Group')
curves.overlay('Group').opts(
opts.Curve(color=dim('Group').categorize({'A': 'red', 'B': 'green'})),
opts.NdOverlay(legend_position='right',show_grid=True, height=300, responsive=True))
What I get is this:
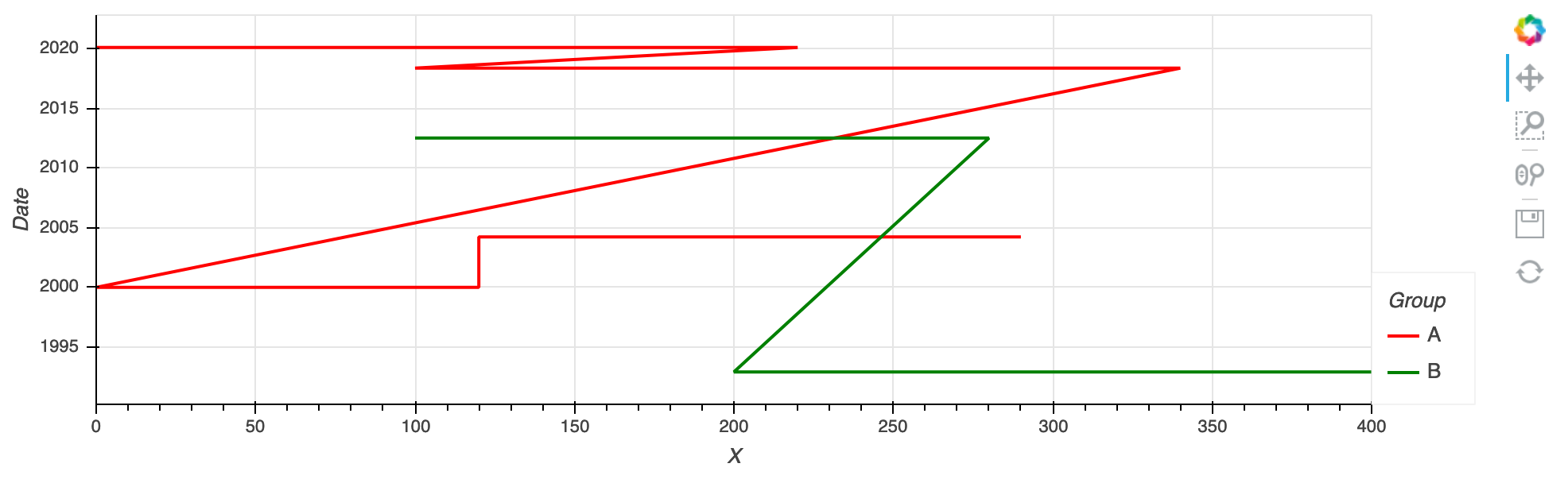
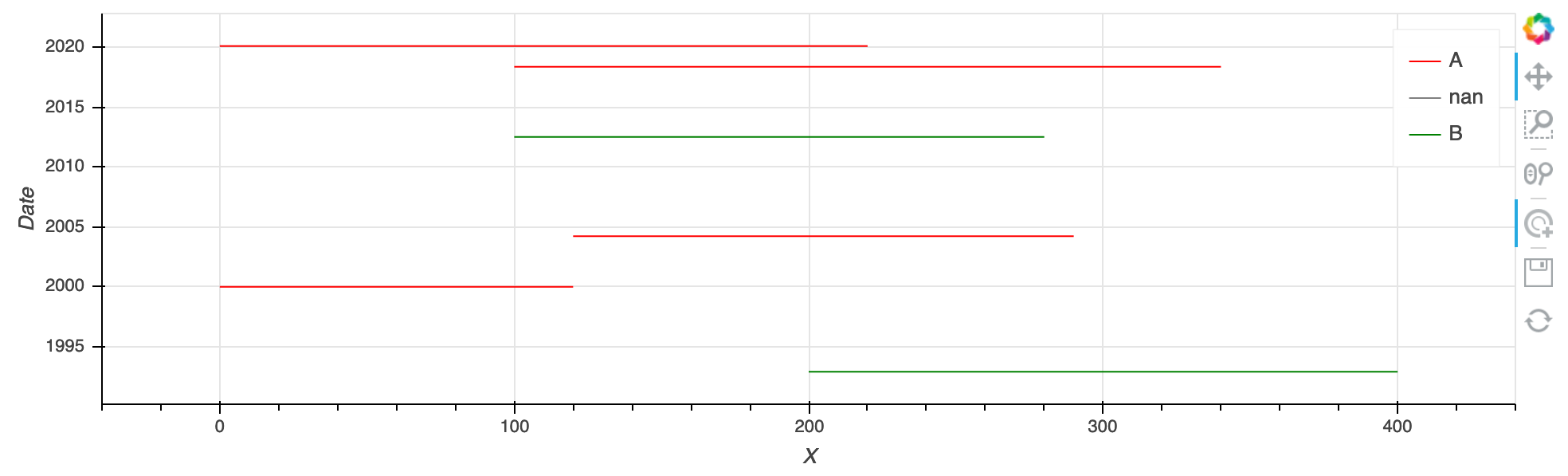
What I would like to get are horizontal lines only (to display in which area I acquired data in which year and of what kind of group). The shape of the dataframe is similar to the one of the example (see link above). So probably I’m not calling
hv.Curvecorrectly. Does anybody have an idea how it’s done right?