Why why do
hv.Scatter(src, x, y) << hv.Histogram(np.histogram(src[y], 20)) << hv.Histogram(np.histogram(src[x], 20))
and
hv.Scatter(src, x, y).hist(num_bins=20, dimension=[x, y])
behave differently with respect to axis and hover labeling? What arguments do I need to supply to the former to get it to behave like the latter?
Specifically, if I lave the code MWE below,
scatter_hist(ds, [('x', 'Apples')], [('y', 'Oranges'), ('z', 'Sauce')], ['x', 'y'])
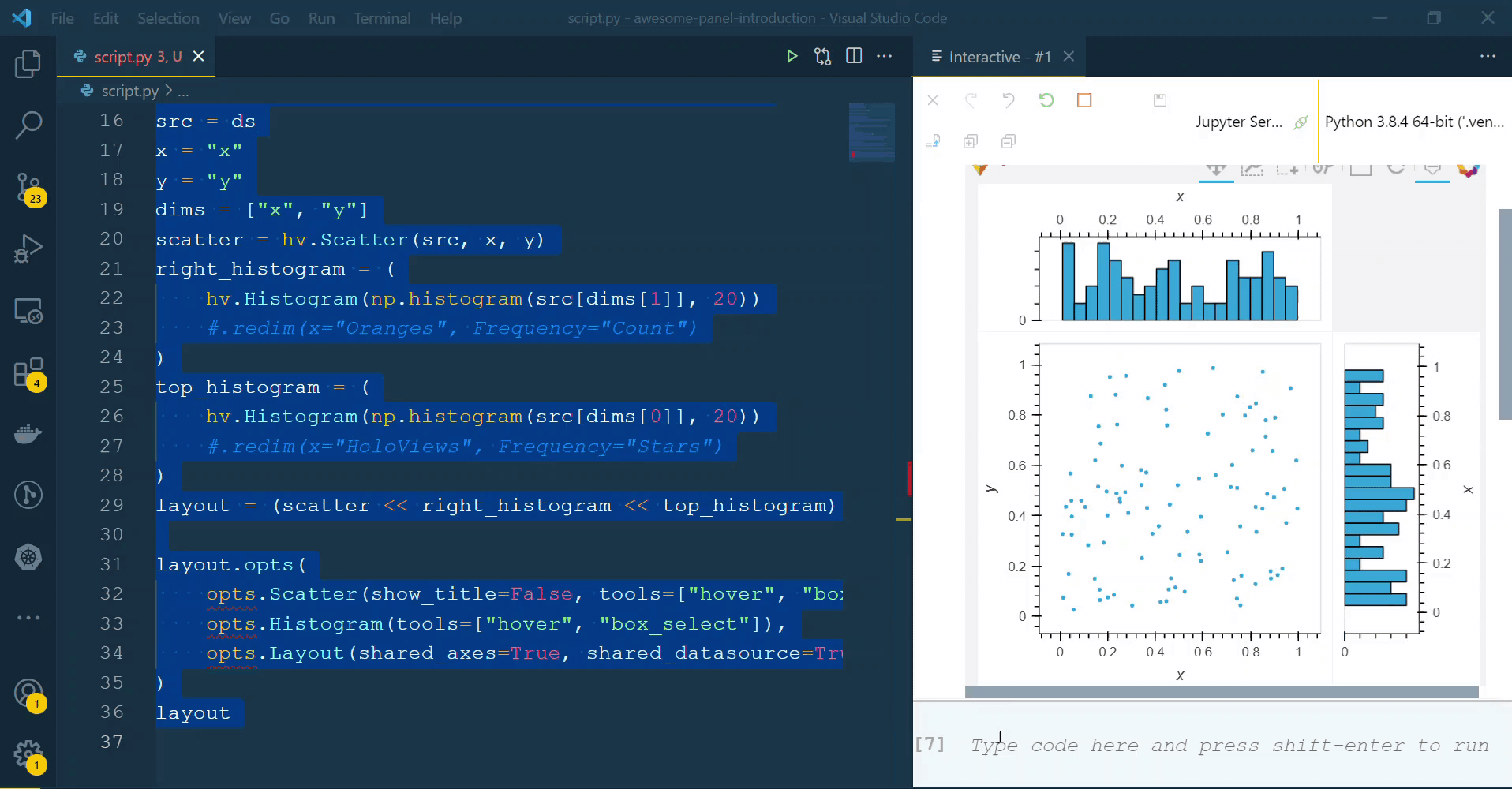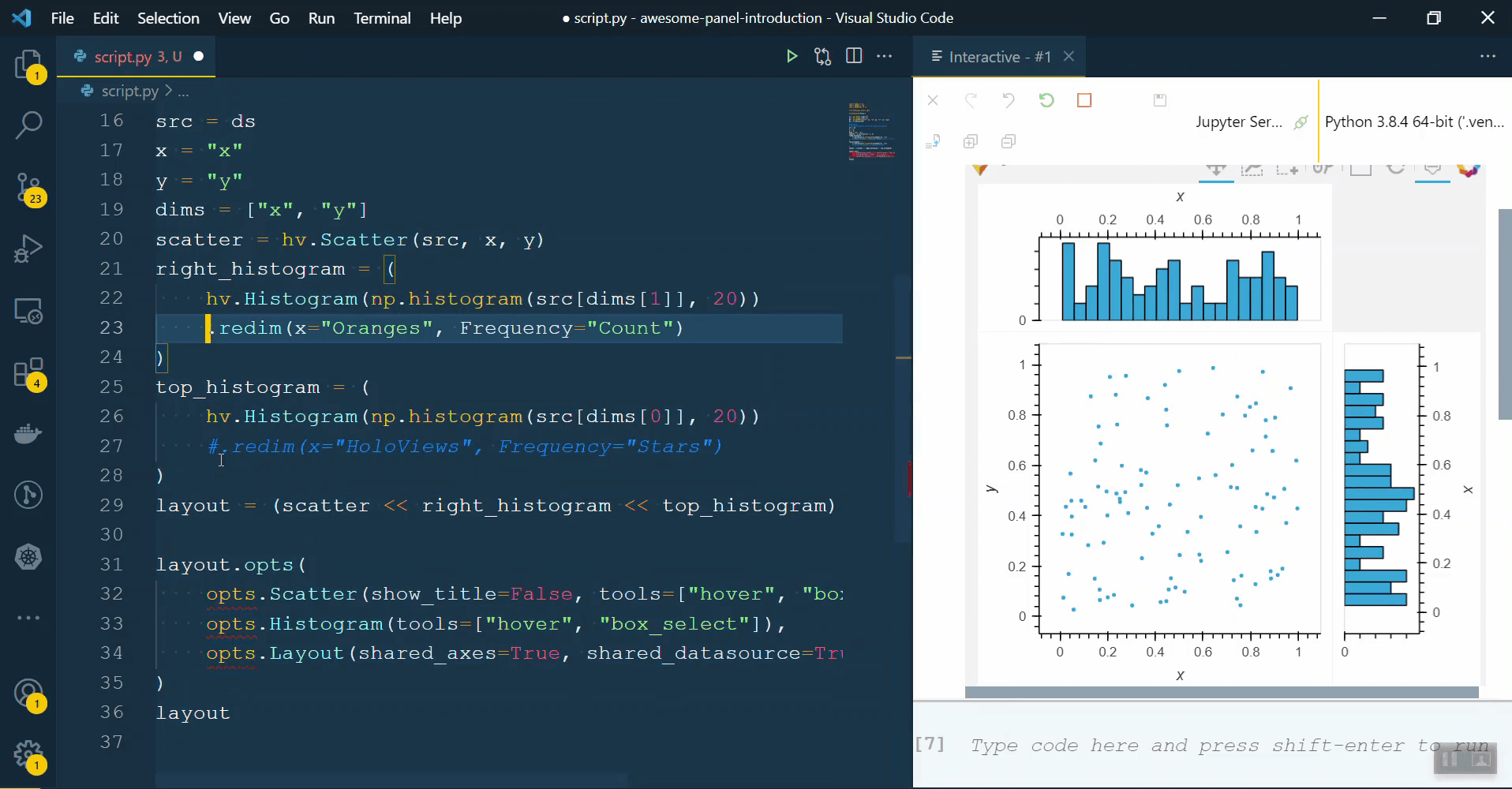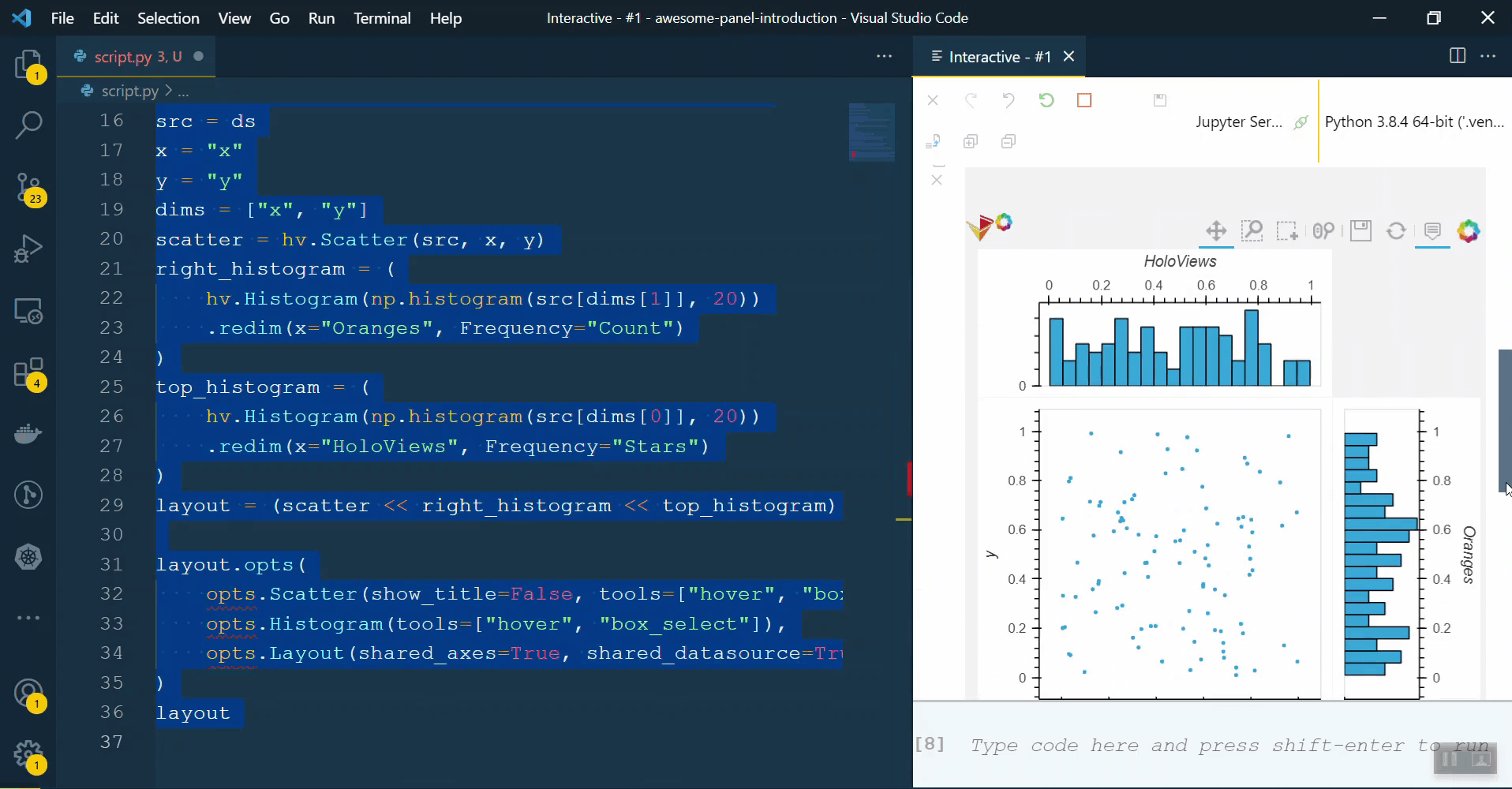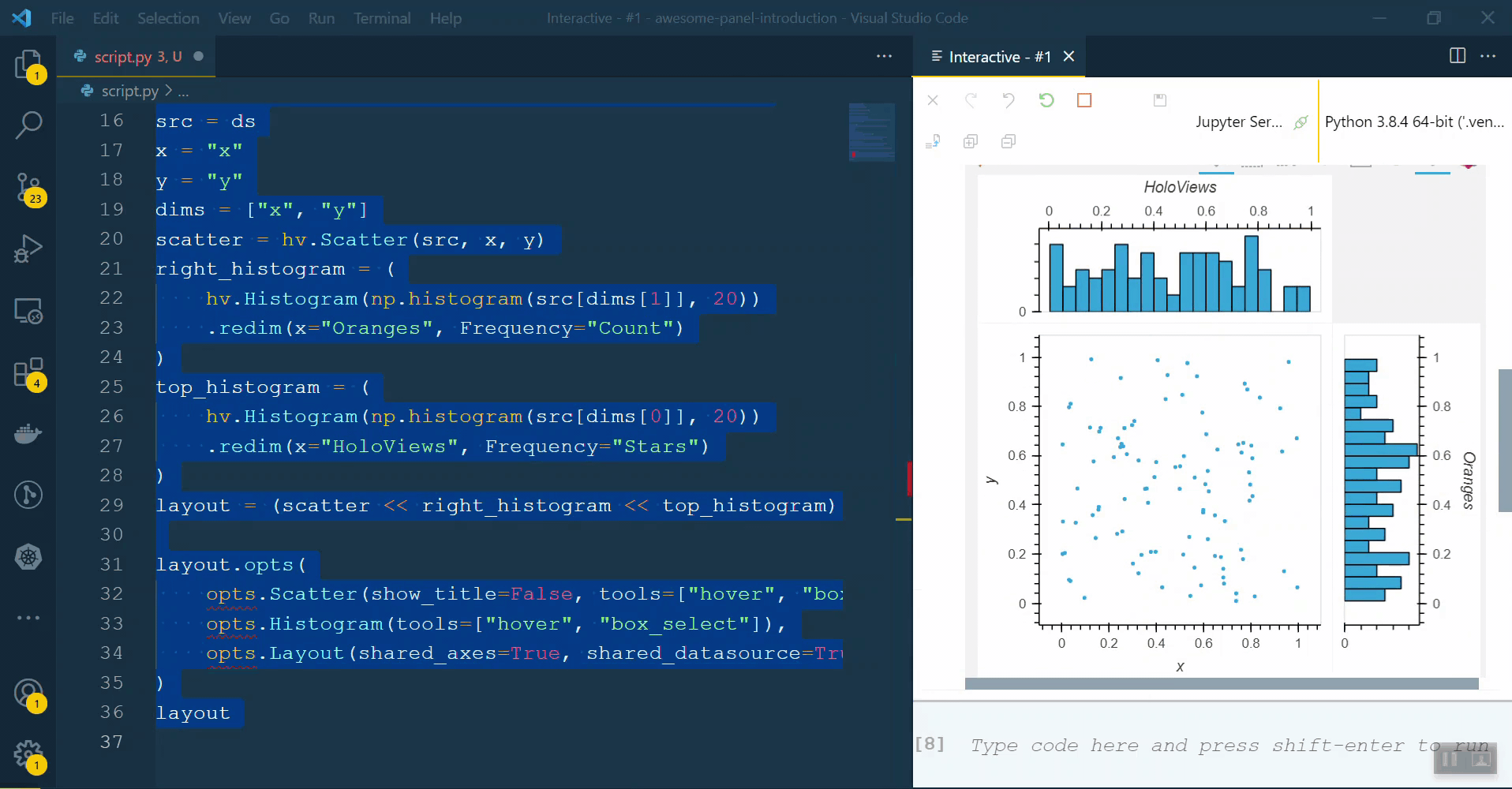
which uses .histogram produces the result on the left while
scatter_hist2(ds, [('x', 'Apples')], [('y', 'Oranges'), ('z', 'Sauce')], ['x', 'y'])
which uses << hv.Histogram produces the result on the right:
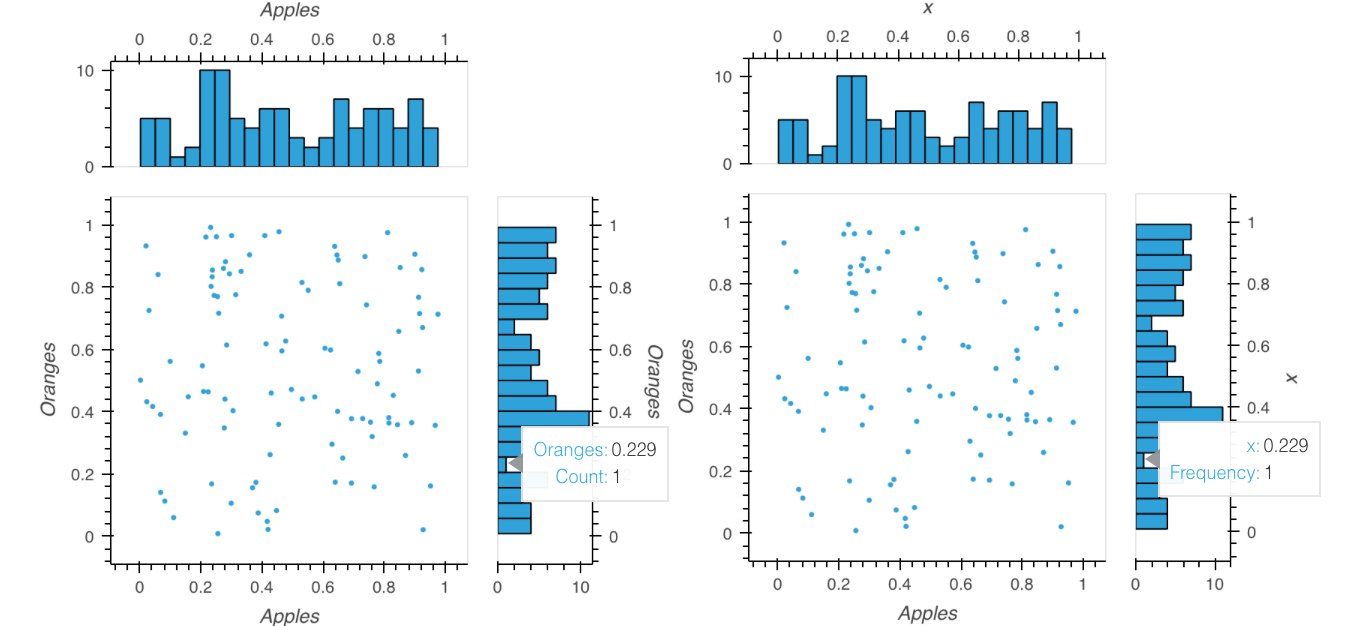
Note that the axes and hover in the latter do not use the provided labels for the data, giving x instead of Oranges or Apples.
import numpy as np
import pandas as pd
import holoviews as hv
from holoviews import opts
hv.extension('bokeh')
xs = np.random.rand(100)
ys = np.random.rand(100)
df = pd.DataFrame({'x': xs, 'y': ys, 'z': xs*ys})
ds = hv.Dataset(df)
def scatter_hist(src, x, y, dims):
p = hv.Scatter(src, x, y).hist(num_bins=20, dimension=dims).opts(
opts.Scatter(show_title=False, tools=['hover','box_select']),
opts.Histogram(tools=['hover','box_select']),
opts.Layout(shared_axes=True, shared_datasource=True, merge_tools=True)
)
return p
def scatter_hist2(src, x, y, dims):
p = (hv.Scatter(src, x, y) << hv.Histogram(np.histogram(src[dims[1]], 20)) << hv.Histogram(np.histogram(src[dims[0]], 20)) ).opts(
opts.Scatter(show_title=False, tools=['hover','box_select']),
opts.Histogram(tools=['hover','box_select']),
opts.Layout(shared_axes=True, shared_datasource=True, merge_tools=True)
)
return p