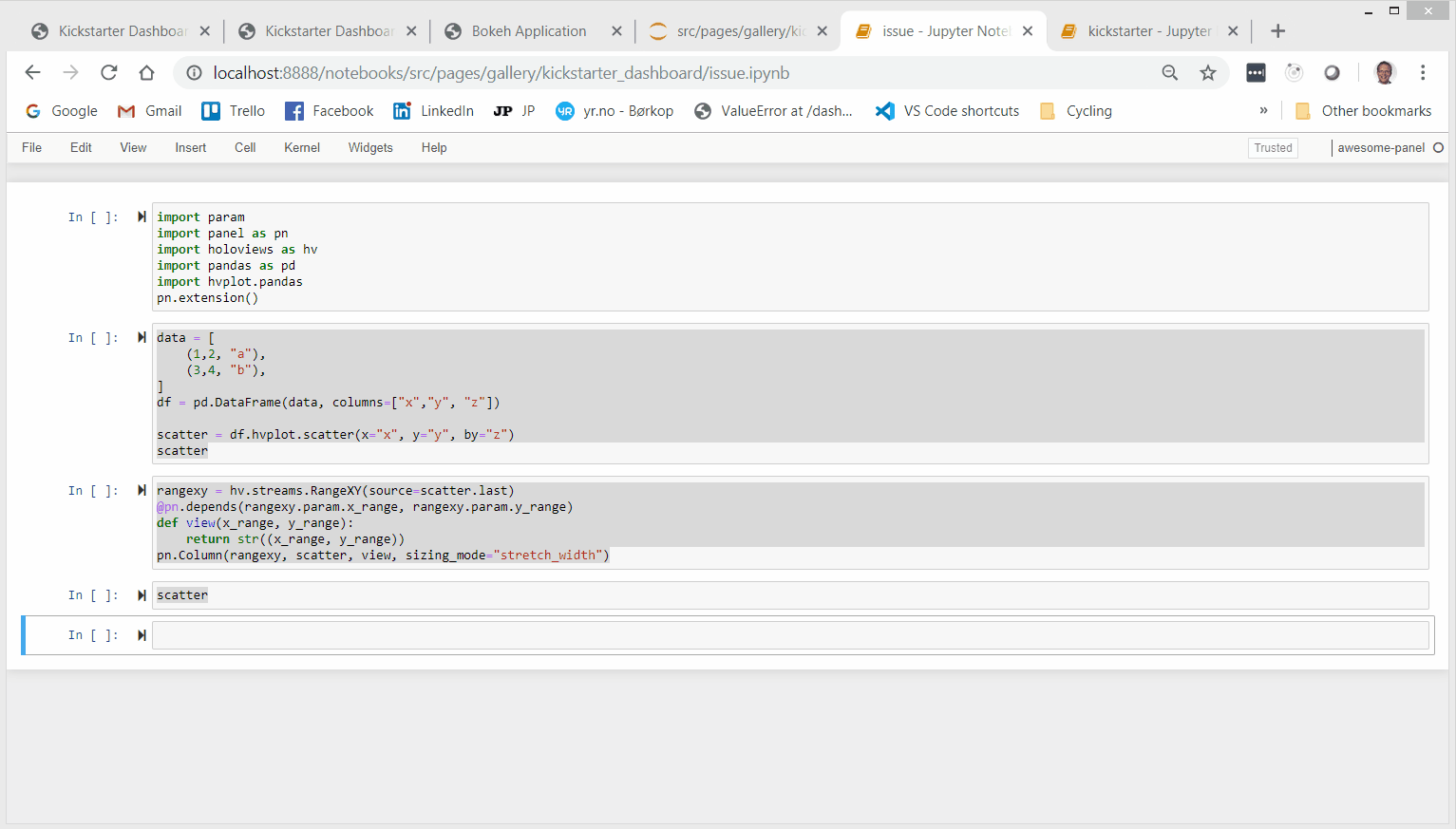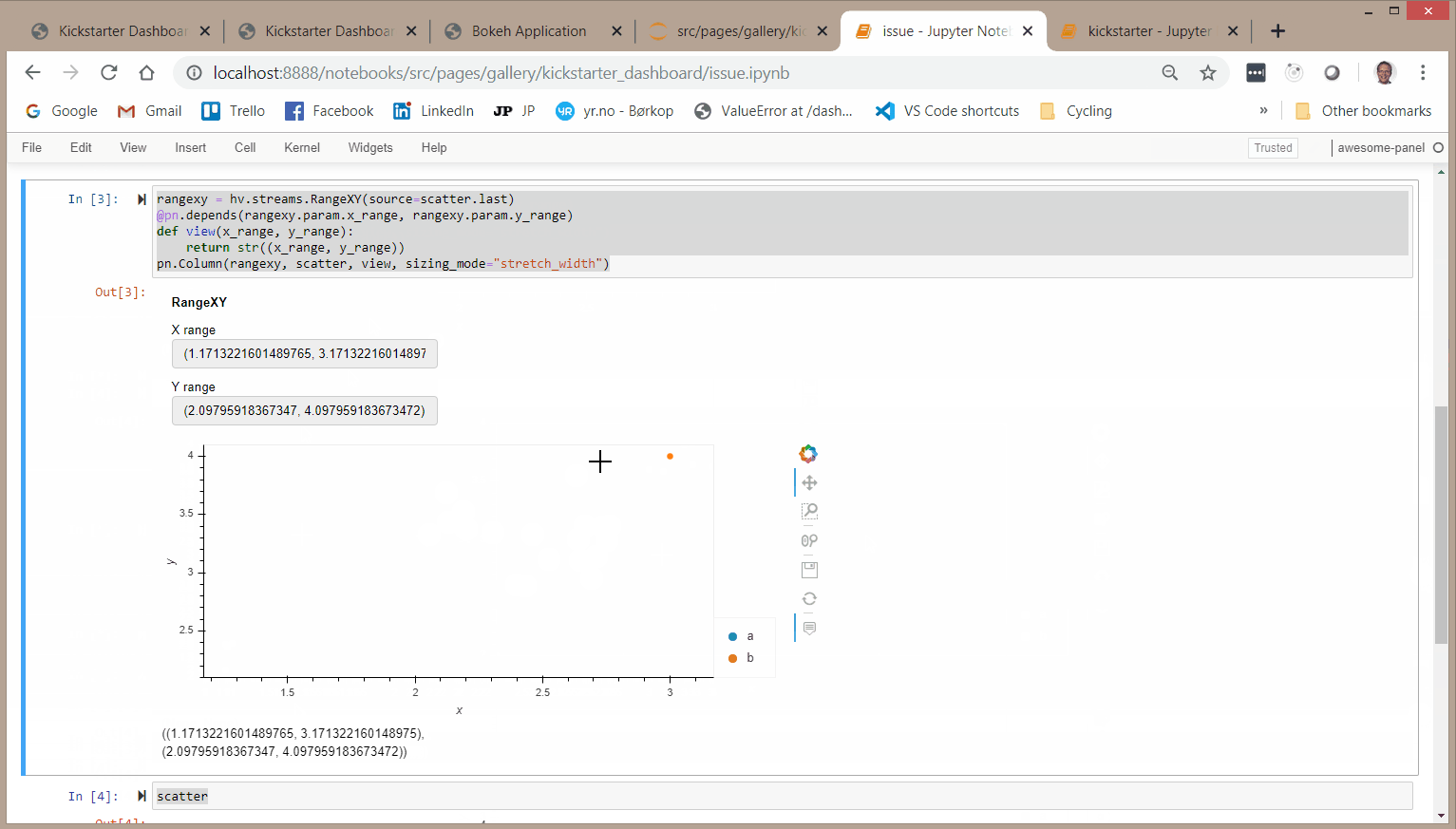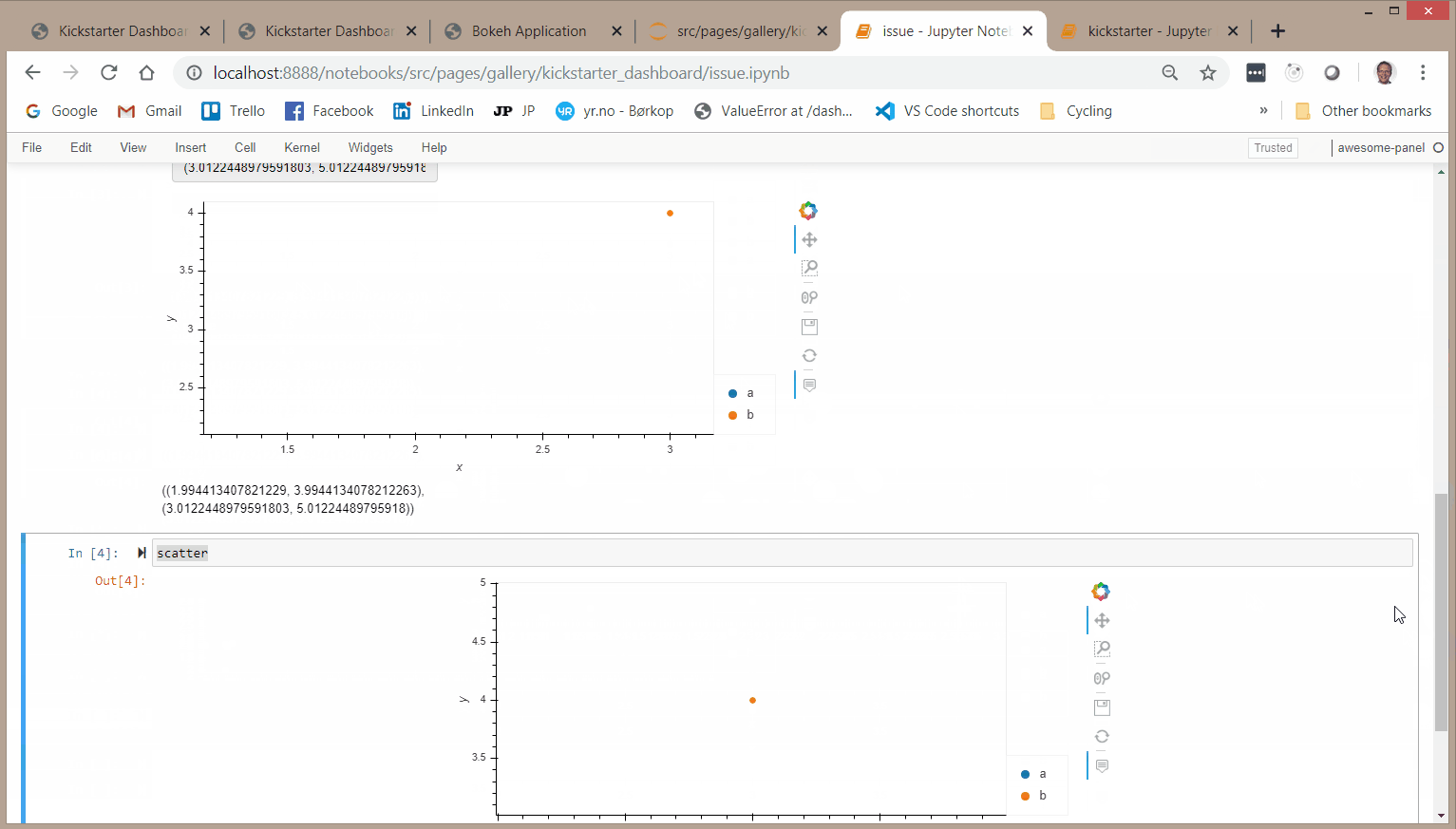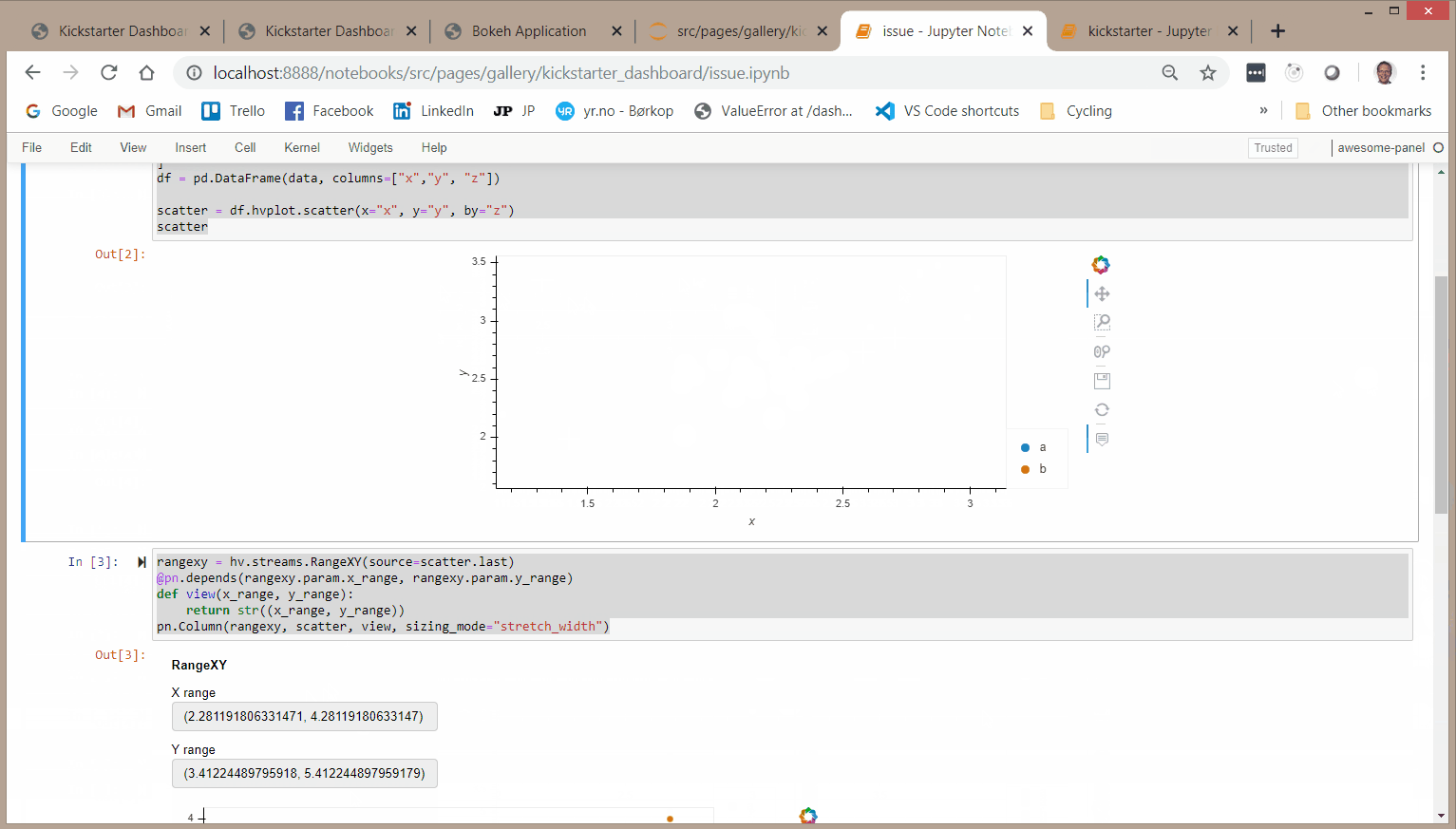
Hi
I was trying to create a Parameterized Dashboard with a Select, a parent and a child plot. The parent and child plot both depending on the selection. The child plot also depending on the range RangeXY of the parent plot. I simply could not get it working in a meaningfull way as it turns out I simply don’t understand the behavior of the @param.depends annotation.
So I’ve tried to create a smaller example below to hopefully get some help.
import param
columns=["a", "b", "c", "d"]
class Dashboard(param.Parameterized):
categories = param.Selector(objects=columns)
data = param.String(columns[0])
@param.depends('categories')
def set_data(self):
self.data=self.categories
@param.depends("categories")
def view_categories(self):
return "Category: " + self.categories
@param.depends("data")
def view_plot(self):
return "Plot: " + self.data
dashboard = Dashboard()
pn.Column(dashboard.param.categories, dashboard.param.data, dashboard.view_categories, dashboard.view_plot)
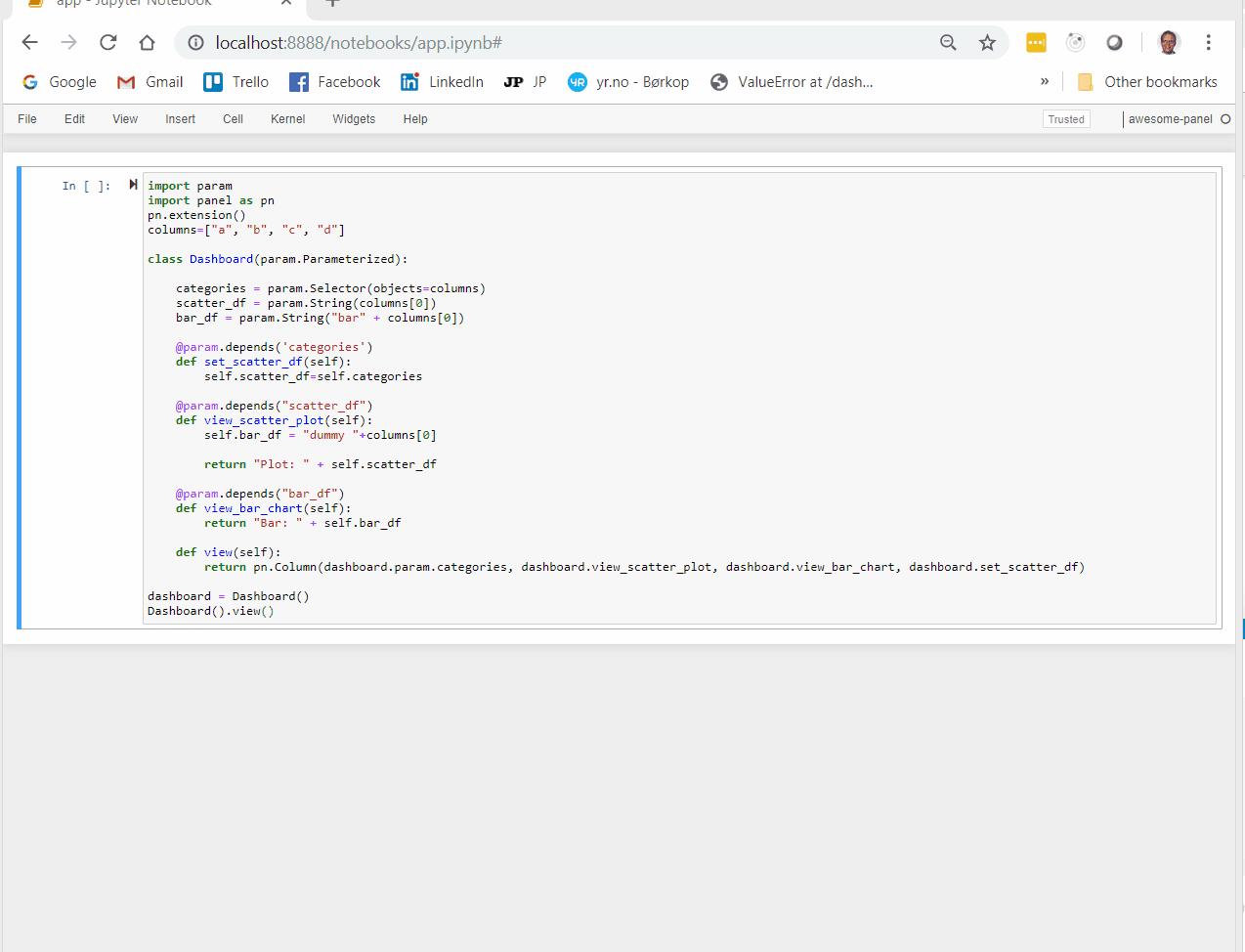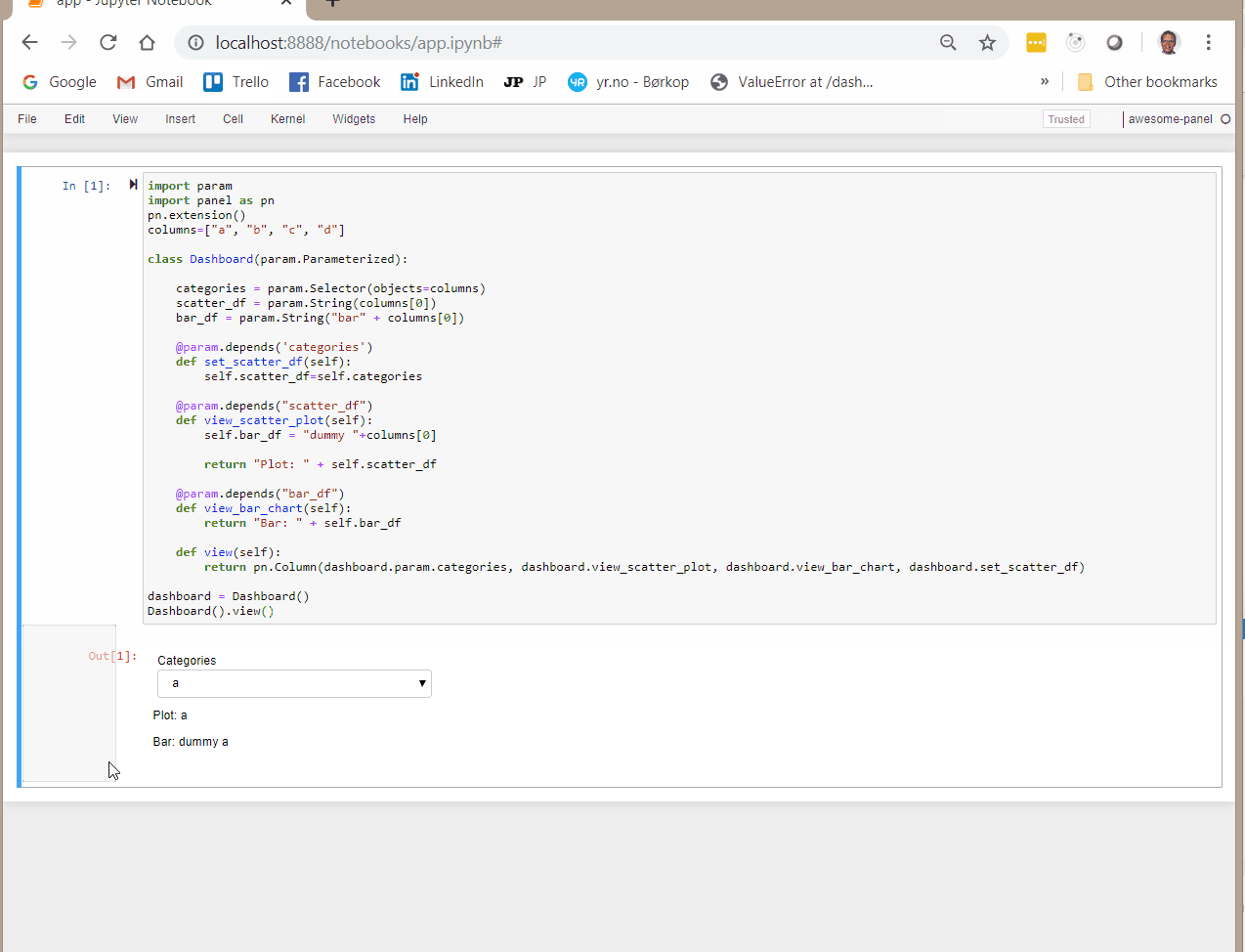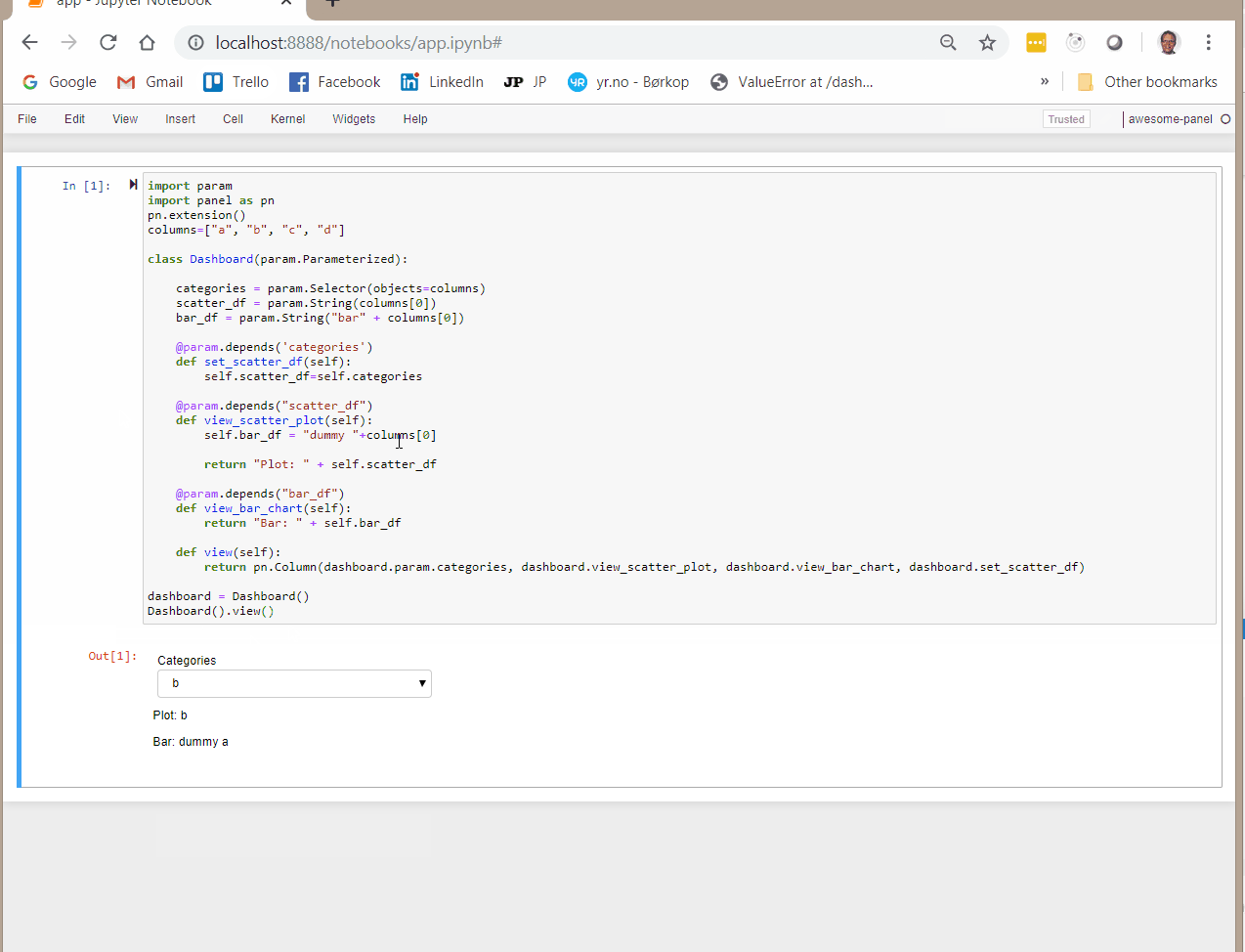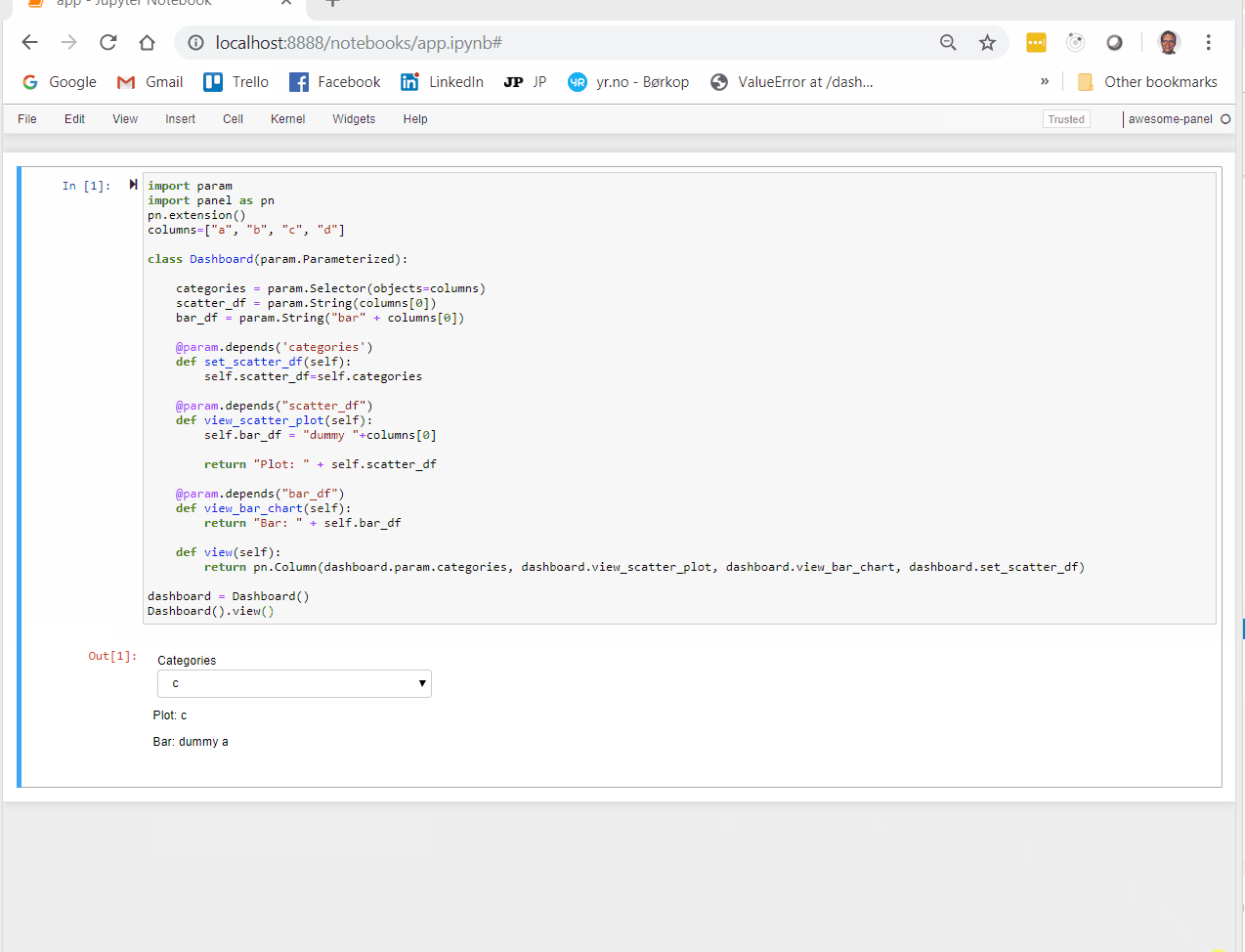
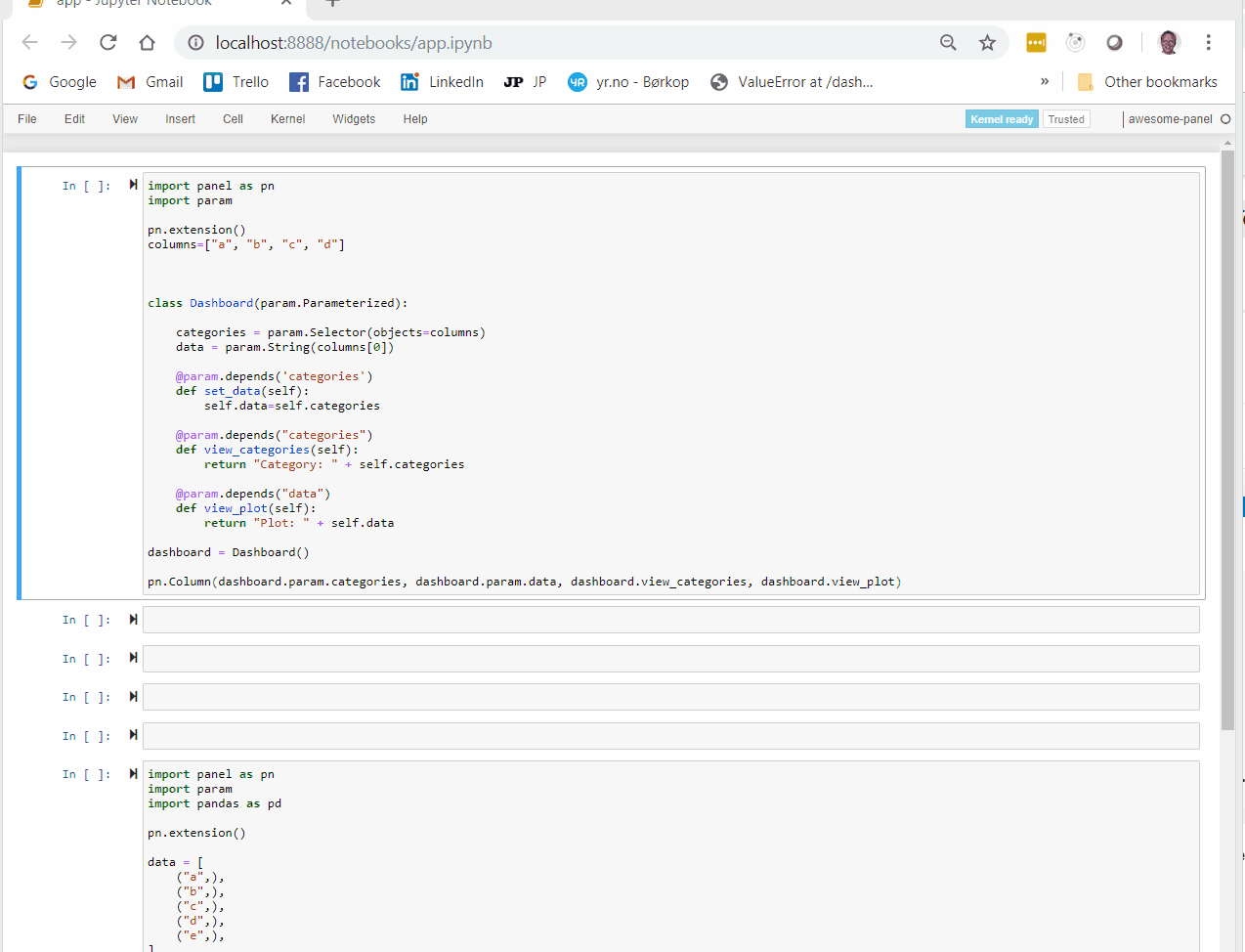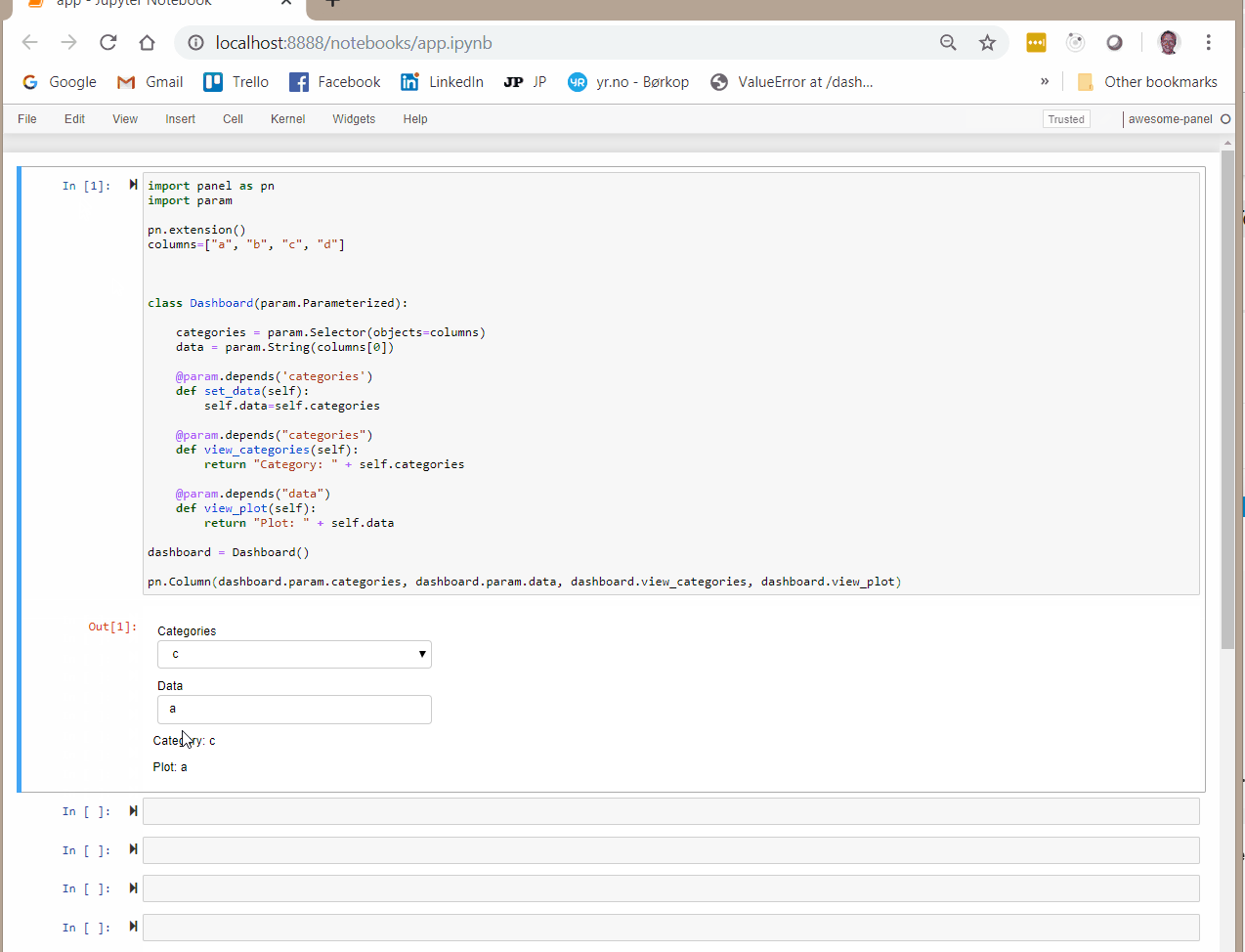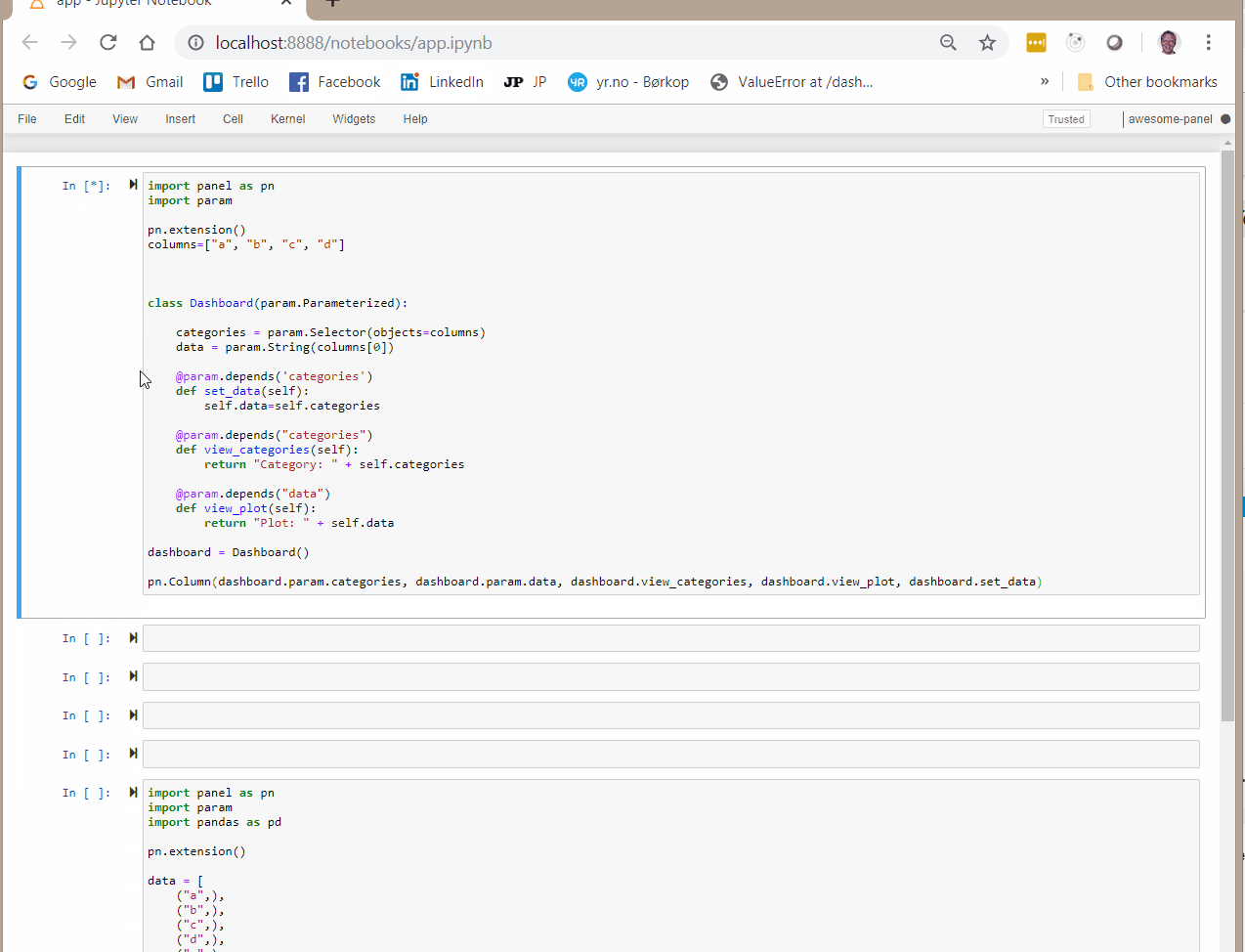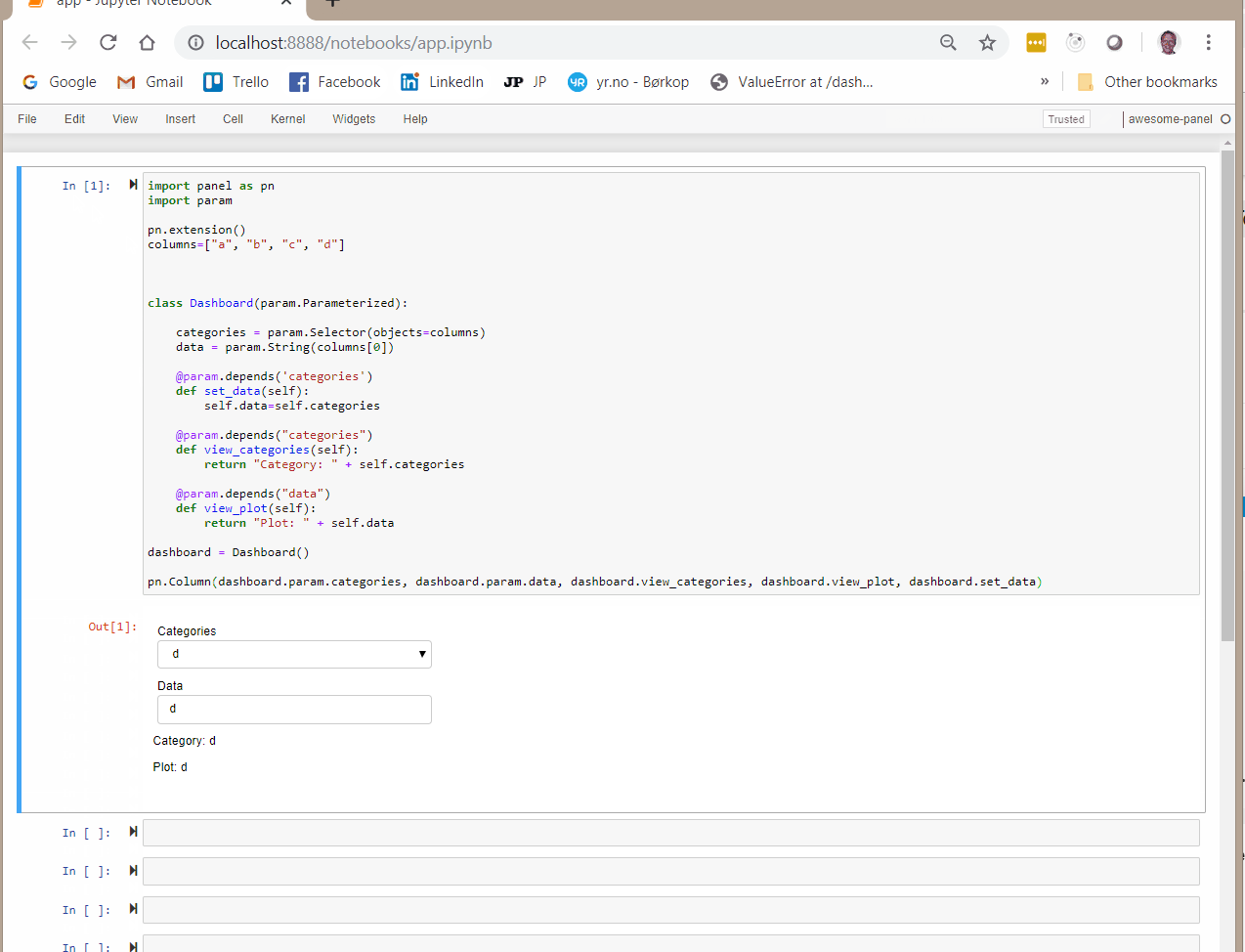
When using this Dashboard I would expect all params and views to change when I change categories using the drop down selection. But it does not.
If instead I add dashboard.set_data to the pn.Column then everything get’s reactive.
pn.Column(dashboard.param.categories, dashboard.param.data, dashboard.view_categories, dashboard.view_plot, dashboard.set_data)
I just don’t understand why I need to add set_data to the pn.Column in order for it to get triggered? It does not display anything and I don’t wan’t it to.
To me that is counter intuitive. And it actually took me a long time to figure out. I tried all sorts of things to make it work before I found out this was nescessary.