Hi all,
It took me a while to get around the document lock issues, but I’ve found a way to supply a panel app with a worker-thread that gets live-data.
Others will probably also deal with this issue, so I decided to show my approach:
Notebook 1 - Pub
import pandas as pd
import numpy as np
from streamz import Stream
from dask.distributed import Client, Pub, Sub
import warnings
warnings.filterwarnings('ignore')
client = Client(n_workers=8)
pub = Pub('test',client=client)
client
This will create a dask pub/sub stream, which you can use to distribute your data:
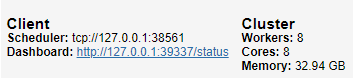
Copy, the scheduler port. You will need it for the 2nd script.
Now let’s define some processing pipeline to transform data, using the streamz library (you can also directly use pub.put(), if you won’t do any processing):
def _put(x):
pub.put(x)
# Some pipeline to be defined
source = Stream()
source.sink(_put)
Finally, let’s put some stuff in our stream:
for i in range(100):
# Sending random dataframes with x,y,z
x = np.random.rand(1)
y = np.random.rand(1)
z = np.random.rand(1)
source.emit(pd.DataFrame({"x":x,"y":y,"z":z}).set_index("x"))
Notebook 2 - Sub (panel app)
import holoviews as hv
import pandas as pd
import numpy as np
import threading
import panel as pn
from panel.io import unlocked
from holoviews.streams import Pipe, Buffer
from dask.distributed import Client, Pub, Sub
hv.extension('bokeh')
# Use the same scheduler
client = Client("tcp://127.0.0.1:38561")
sub = Sub('test',client=client)
client
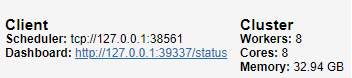
Now, let’s define our buffer & plot:
# Example df for buffer
df = pd.DataFrame({"x":np.array([]),
"y":np.array([]),
"z":np.array([])}).set_index("x")
# Buffer that updates plot
buffer = Buffer(data=df)
# Some example scatter plot
dmap = hv.DynamicMap(hv.Scatter, streams=[buffer]).opts(bgcolor='black', color='z', show_legend=False)
We still need to get the data from the pub/sub stream, so let’s put them in a local buffer, called ‘temp’:
# Store pub/sub result in local buffer
temp = []
# Panel object
p1 = pn.Column(dmap)
# Function to put things into plot buffer
def to_buffer():
with unlocked():
while len(temp):
msg = temp.pop()
buffer.send(msg)
# Function to pop elements from pub/sub stream
def _pop():
# This for-loop will continously try to pop elements
for msg in sub:
temp.append(msg)
# Print length of pub/sub stream
print(f"{len(sub.buffer):<20}",end="\r")
# Launch separate thread for pub/sub
worker = threading.Thread(target=_pop)
worker.start()
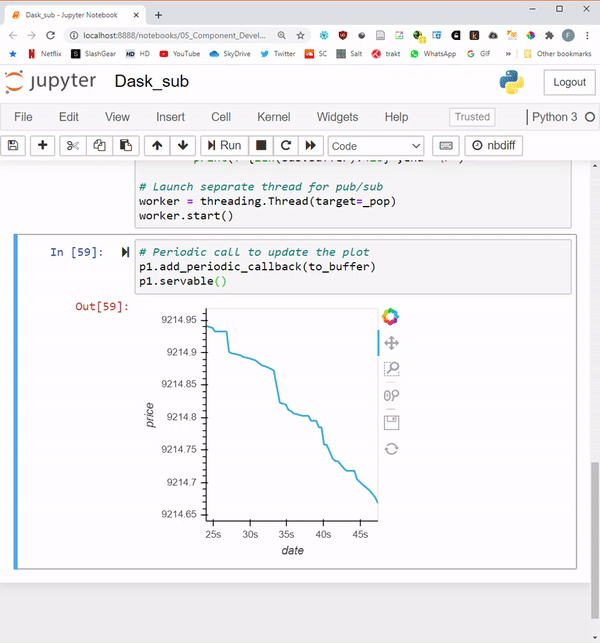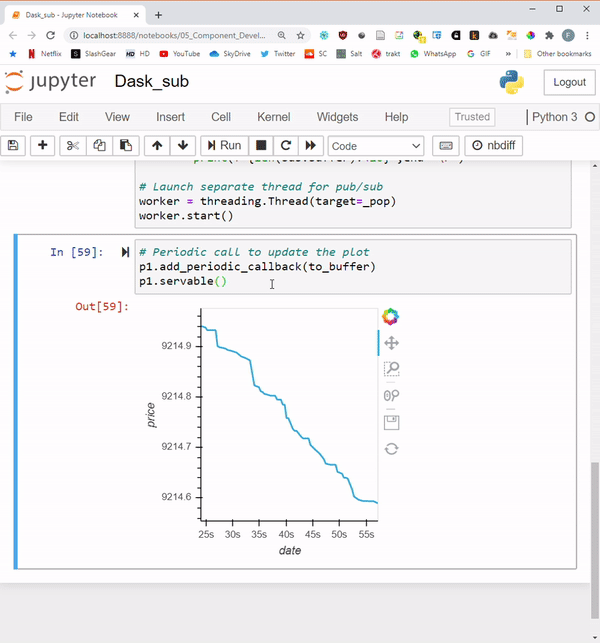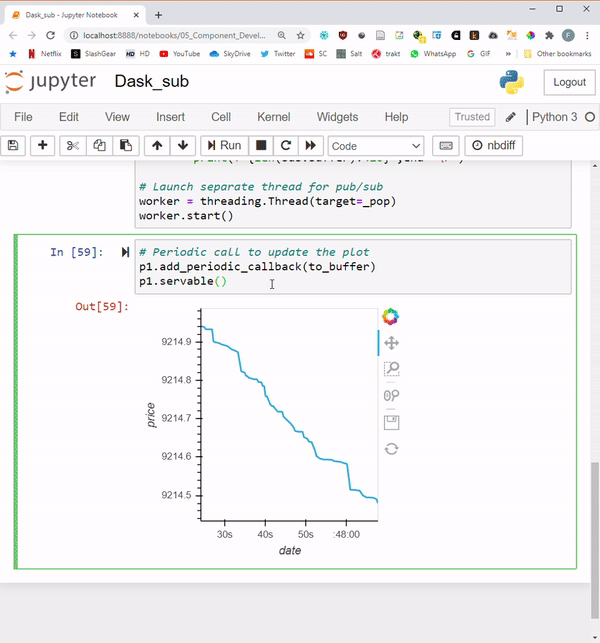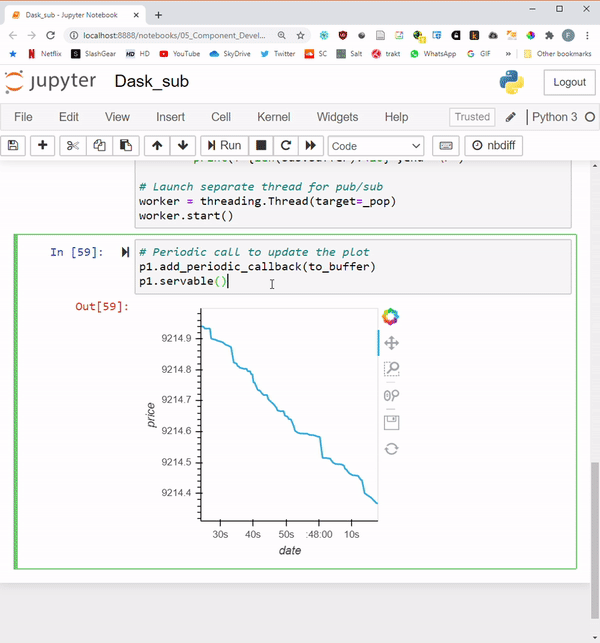
Finally, let’s add a periodic callback with the default of 500ms frequency, and make the app servable.
# Periodic call to update the plot
p1.add_periodic_callback(to_buffer)
p1.servable()
Serve with panel serve:
panel serve --port 5006 --ssl-certfile cert.pem --ssl-keyfile private.key --allow-websocket-origin app.materialindicators.com --num-procs 8 Dask_sub.ipynb
Results:
Let’s load the app on multiple windows to see what users would see:
Trigger the data generation in the first notebook with this cell:
for i in range(100):
# Sending random dataframes with x,y,z
x = np.random.rand(1)
y = np.random.rand(1)
z = np.random.rand(1)
source.emit(pd.DataFrame({"x":x,"y":y,"z":z}).set_index("x"))
The GIF below shows the results in action
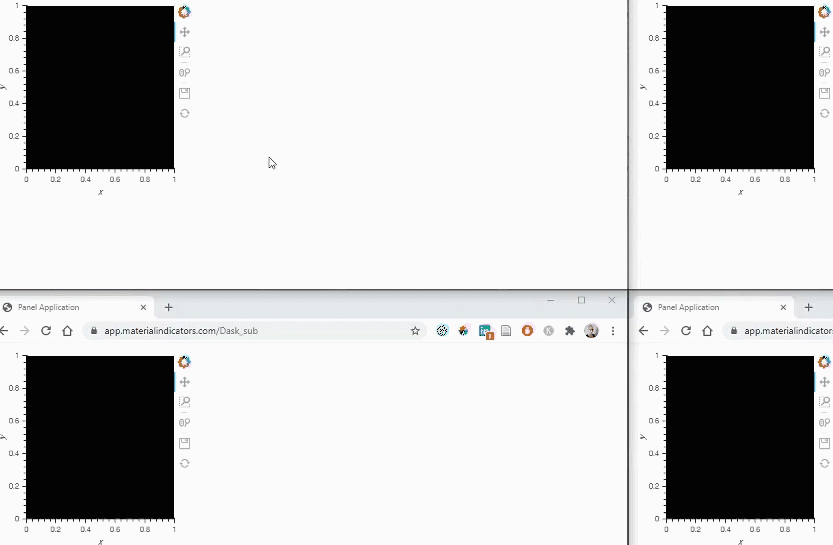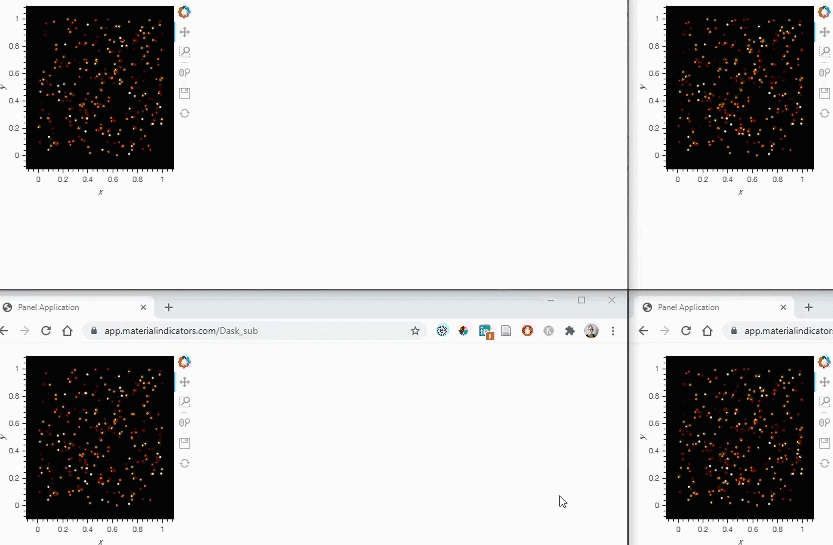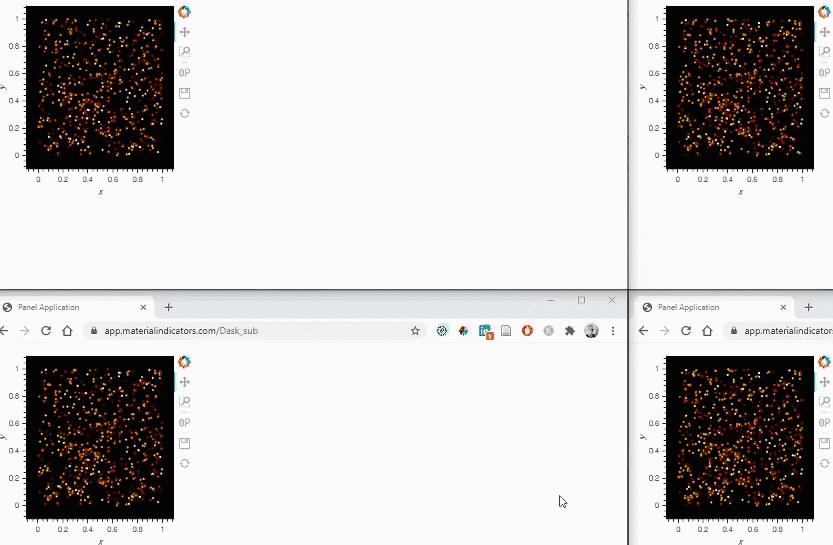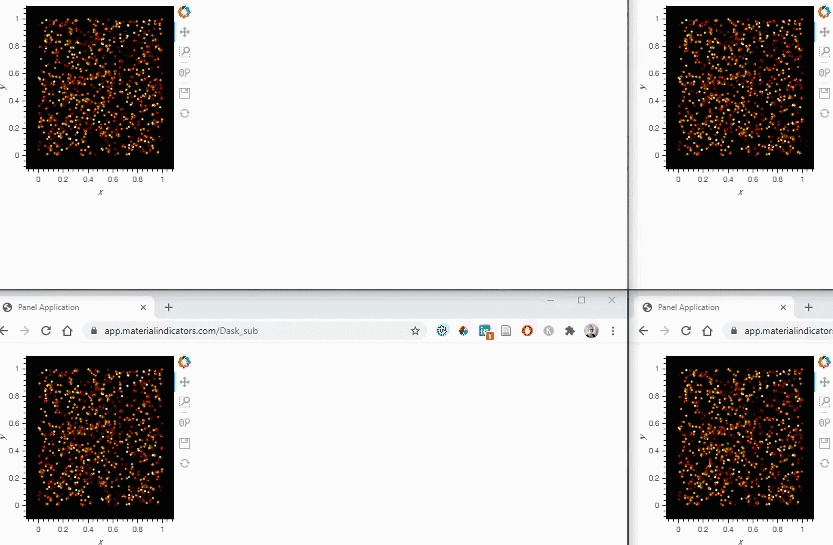
That’s all. I hope others will find it useful too!