hi @ahuang11
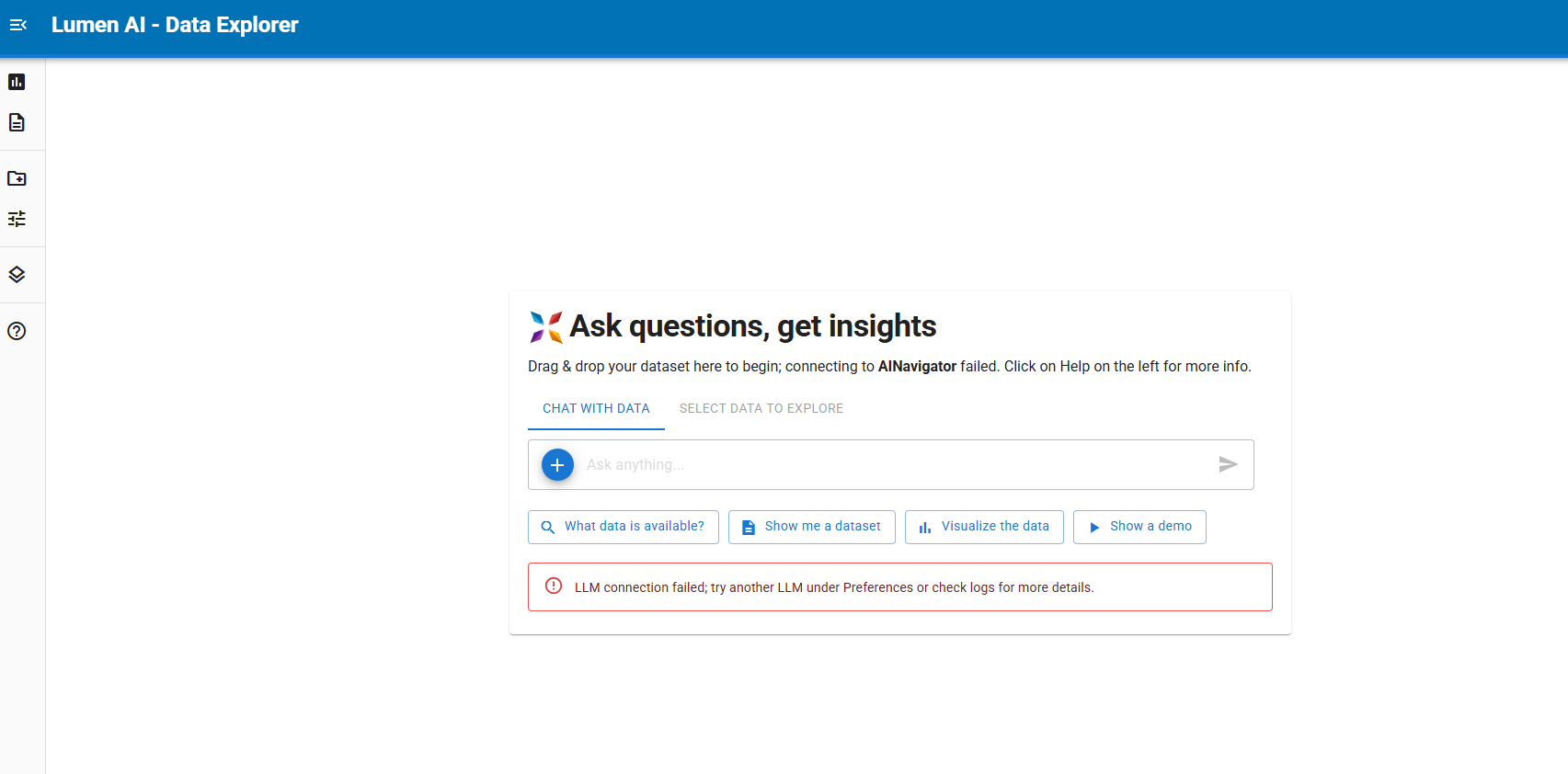
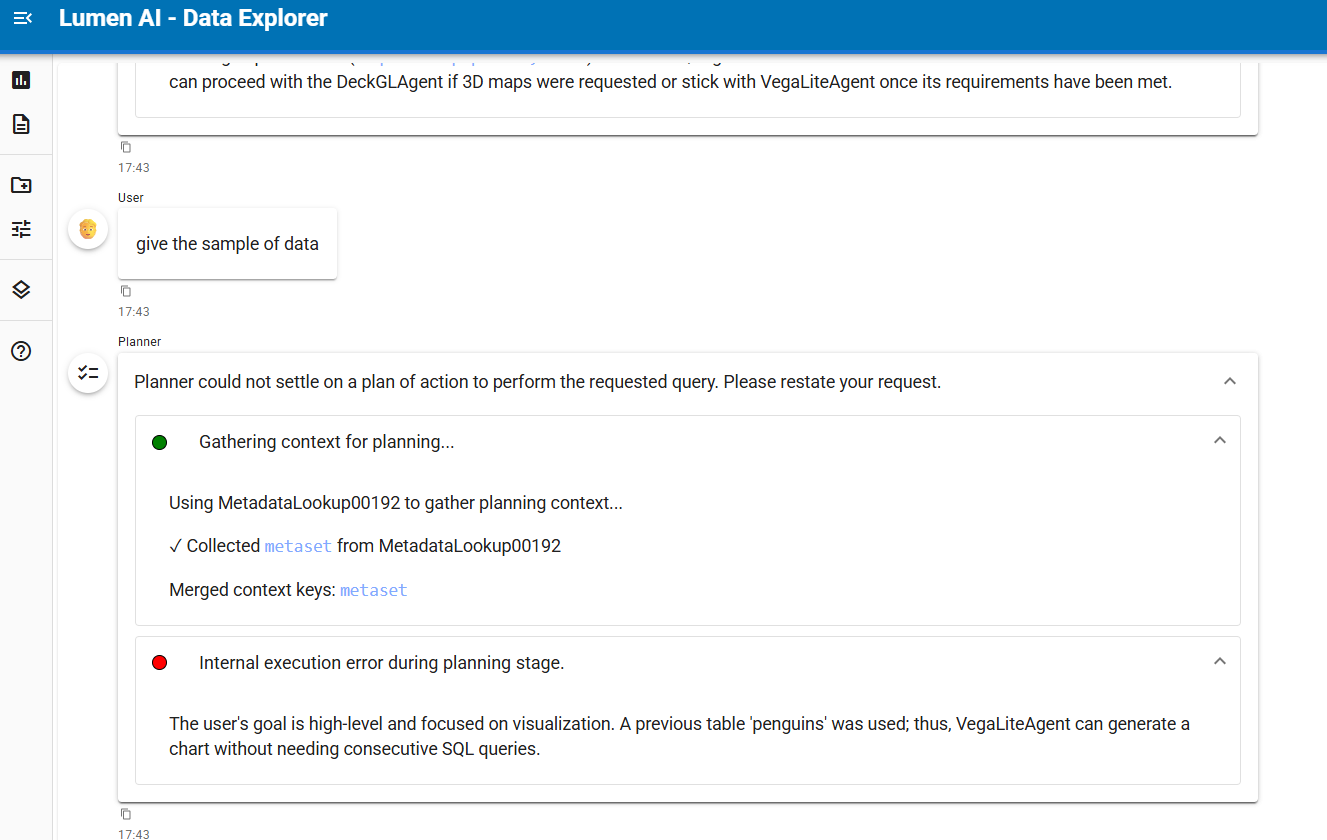
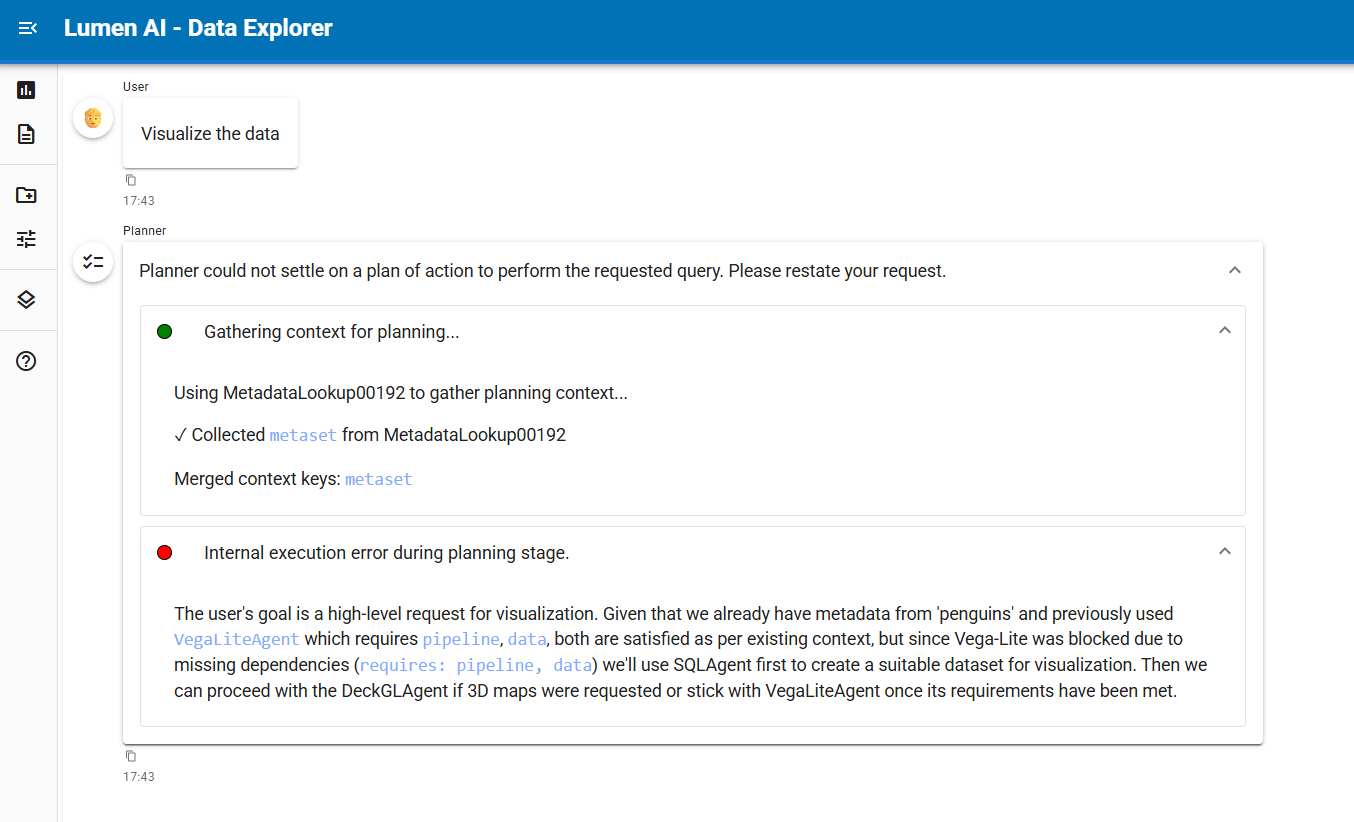
thanks I already pip from github unfortunately still have error, below is the log:
2026-02-05 09:04:44,213 Starting Bokeh server version 3.8.2 (running on Tornado 6.5.4)
2026-02-05 09:04:44,215 User authentication hooks NOT provided (default user enabled)
2026-02-05 09:04:44,221 Bokeh app running at: http://localhost:5025/test_lumen
2026-02-05 09:04:44,221 Starting Bokeh server with process id: 3355739
2026-02-05 09:04:52,039 ______________________________________________________________________________________________________________________
2026-02-05 09:04:52,039 New Session: Started
2026-02-05 09:04:53,566 WebSocket connection opened
2026-02-05 09:04:53,567 ServerConnection created
2026-02-05 09:04:53,863 Input messages: 1 messages including system
2026-02-05 09:04:53,863 Message 0 (u): Ready? "Y" or "N"
2026-02-05 09:04:53,863 LLM Model: 'llama3:latest'
2026-02-05 09:04:54,074 [MetadataLookup] Starting _update_vector_store for 1 sources
2026-02-05 09:04:54,074 [MetadataLookup] Processing source ProvidedSource00000
2026-02-05 09:04:54,102 [MetadataLookup] Starting _update_vector_store for 1 sources
2026-02-05 09:04:54,102 [MetadataLookup] Skipping source ProvidedSource00000 - already in progress
2026-02-05 09:04:54,105 [MetadataLookup] Waiting for 1 tasks to complete
2026-02-05 09:04:54,105 [MetadataLookup] Upserting 1 enriched entries
2026-02-05 09:04:54,119 [MetadataLookup] Successfully upserted 1 entries
2026-02-05 09:04:54,119 [MetadataLookup] All table metadata tasks completed.
2026-02-05 09:04:54,119 [MetadataLookup] Cleaning up sources: []
2026-02-05 09:04:54,124 [MetadataLookup] Cleaning up sources: ['ProvidedSource00000']
2026-02-05 09:04:54,124 [MetadataLookup] Removed ProvidedSource00000 from in-progress
2026-02-05 09:04:54,124 [MetadataLookup] Removed empty vector_store_id 139884884941408
2026-02-05 09:04:54,390 LLM Response: ChatCompletion(id='chatcmpl-207', choices=[Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='Y', refusal=None, role='assistant', annotations=None, audio=None, function_call=None, tool_calls=None))], created=1770253494, model='llama3:latest', object='chat.completion', service_tier=None, system_fingerprint='fp_ollama', usage=CompletionUsage(completion_tokens=2, prompt_tokens=19, total_tokens=21, completion_tokens_details=None, prompt_tokens_details=None))
---
2026-02-05 09:06:57,506 ______________________________________________________________________________________________________________________
2026-02-05 09:06:57,506 New Message: 'Show me a dataset'
2026-02-05 09:06:57,703 Dropping a patch because it contains a previously known reference (id='p1061'). Most of the time this is harmless and usually a result of updating a model on one side of a communications channel while it was being removed on the other end.
2026-02-05 09:06:58,200 [MetadataLookup] Starting _update_vector_store for 1 sources
2026-02-05 09:06:58,200 [MetadataLookup] Processing source ProvidedSource00000
2026-02-05 09:06:58,214 [_query_documents] query='Show me a dataset', all=0, visible=all, included=0
2026-02-05 09:06:58,229 [MetadataLookup] Waiting for 1 tasks to complete
2026-02-05 09:06:58,229 [MetadataLookup] Upserting 1 enriched entries
2026-02-05 09:06:58,229 All items already exist in the vector store.
2026-02-05 09:06:58,229 [MetadataLookup] Successfully upserted 1 entries
2026-02-05 09:06:58,229 [MetadataLookup] All table metadata tasks completed.
2026-02-05 09:06:58,229 [MetadataLookup] Cleaning up sources: ['ProvidedSource00000']
2026-02-05 09:06:58,229 [MetadataLookup] Removed ProvidedSource00000 from in-progress
2026-02-05 09:06:58,230 [MetadataLookup] Removed empty vector_store_id 139884884941408
2026-02-05 09:06:58,443 Planner00191.prompts['main']['template']:
Do not excessively reason in responses; there are chain_of_thought fields for that, but those should also be concise (1-2 sentences).
The current date time is Feb 05, 2026 09:06 AM
You are the team lead responsible for creating a step-by-step plan to address user queries by assigning subtasks to specialized actors (agents and tools).
CRITICAL: Dependency Management
- ALWAYS check if an agent's Requires are satisfied before including it in your plan
- If ❌ BLOCKED, find actors with "Provides" matching the missing Requires and add them as prior steps
- Dependencies must be resolved in the correct order - providers before consumers
Ground Rules:
- Plan in one shot, do not assume you can replan
- Respect dependency chains: assign tasks only when input Requires are met
- Leverage existing memory instead of regenerating information if possible
- Stay within scope of the user's request (don't plot unless asked, etc.)
- It's often unnecessary to use the same actor multiple times in a single plan
- NEVER use the same actor consecutively - combine multiple tasks for the same actor into a single step
- Never mention a lack of data in your plan - assume your actors will handle data discovery
- Do not ignore the actor's exclusions and conditions
- When keys are already present in memory, utilize them to construct your plan efficiently—avoid assigning an actor to produce memory keys that are already available
- **Visualization continuity**: Prefer the previously used visualization agent if its conditions still apply to the current request
- **Multi-metric queries**: When user asks for multiple metrics (e.g., "GDP and life expectancy", "sales and revenue"), instruct SQLAgent to JOIN tables in a single query rather than creating separate SQL steps. Example instruction: "Join GDP and life expectancy tables on country and year, selecting all metrics needed for visualization"
- Tools require actor interpretation - always follow-up tools with agents
# Available Actors with Dependency Analysis
## Tools
### `MetadataLookup` ✅ READY
Discovers relevant tables using vector search, providing context for other agents. Not to be used for finding tables for further analysis (e.g. SQL), because it does not provide a schema.
Provides: `metaset`
Conditions for use:
- Best paired with ChatAgent for general conversation about data
- Avoid if table discovery already performed for same request
- Not useful for data related queries
## Agents
### `ChatAgent` ✅ READY
Provides conversational assistance and interprets existing results.
Handles general questions, technical documentation, and programming help.
When data has been retrieved, explains findings in accessible terms.
Conditions:
- Use for general conversation that doesn't require fetching or querying data
- Use for technical questions about programming, functions, methods, libraries, or APIs
- Use when user asks to 'explain', 'interpret', 'analyze', 'summarize', or 'comment on' existing data in context
- NOT when user asks to 'show', 'get', 'fetch', 'query', 'filter', 'calculate', 'aggregate', or 'transform' data
- NOT for creating new data transformations - only for explaining data that already exists
### `SQLAgent` ✅ READY
Creates and executes SQL queries to retrieve, filter, aggregate, or transform data.
Handles table joins, WHERE clauses, GROUP BY, calculations, and other SQL operations.
Generates new data pipelines from SQL transformations.
Provides: `data`, `table`, `sql`, `pipeline`
Conditions:
- Use for querying, filtering, aggregating, or transforming data with SQL
- Use for calculations that require executing SQL (e.g., 'calculate average', 'sum by category')
- Use when user asks to 'show', 'get', 'fetch', 'query', 'find', 'filter', 'calculate', 'aggregate', or 'transform' data
- NOT when user asks to 'explain', 'interpret', 'analyze', 'summarize', or 'comment on' existing data
- NOT useful if the user is using the same data for plotting
Should never be used together with: `DbtslAgent`, `MetadataLookup`, `TableListAgent`
### `VegaLiteAgent` ❌ BLOCKED! Requires: `pipeline`, `table`, `data`
Generates a vega-lite plot specification from the input data pipeline.
Conditions:
- Use for publication-ready visualizations or when user specifically requests Vega-Lite charts
- Use for polished charts intended for presentation or sharing
### `DeckGLAgent` ❌ BLOCKED! Requires: `pipeline`, `table`, `data`
Generates DeckGL 3D map visualizations from geographic data.
Conditions:
- Use for 3D geographic visualizations, map-based data, or when user requests DeckGL/deck.gl
- Use for large-scale geospatial data with latitude/longitude coordinates
- Use for hexbin aggregations, heatmaps, or 3D extruded visualizations on maps
## Current Data Context
Data sources:
- penguins_csv
Existing metadata found: Evaluate if current data is sufficient before requesting more
2026-02-05 09:06:58,443 Characters: 4972
2026-02-05 09:06:58,444 Input messages: 2 messages including system
2026-02-05 09:06:58,444 Message 1 (u): Show me a dataset
2026-02-05 09:06:58,444 LLM Model: 'llama3:latest'
2026-02-05 09:07:00,171 Response model: 'PartialReasoning'
2026-02-05 09:07:00,172 LLM Response: <async_generator object PartialBase.from_streaming_response_async at 0x7f39b6bc5c40>
---
2026-02-05 09:07:00,344 Dropping a patch because it contains a previously known reference (id='p1061'). Most of the time this is harmless and usually a result of updating a model on one side of a communications channel while it was being removed on the other end.
Traceback (most recent call last):
File "/opt/tljh/anaconda3/envs/GEN_AI/lib/python3.12/site-packages/lumen/ai/coordinator/planner.py", line 520, in _compute_plan
raw_plan = await self._make_plan(
^^^^^^^^^^^^^^^^^^^^^^
File "/opt/tljh/anaconda3/envs/GEN_AI/lib/python3.12/site-packages/lumen/ai/utils.py", line 1071, in async_wrapper
return await func(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/tljh/anaconda3/envs/GEN_AI/lib/python3.12/site-packages/lumen/ai/coordinator/planner.py", line 342, in _make_plan
async for reasoning in self.llm.stream(
File "/opt/tljh/anaconda3/envs/GEN_AI/lib/python3.12/site-packages/lumen/ai/llm.py", line 438, in stream
async for chunk in chunks:
File "/opt/tljh/anaconda3/envs/GEN_AI/lib/python3.12/site-packages/instructor/dsl/partial.py", line 364, in from_streaming_response_async
async for item in cls.model_from_chunks_async(json_chunks, **kwargs):
File "/opt/tljh/anaconda3/envs/GEN_AI/lib/python3.12/site-packages/instructor/dsl/partial.py", line 493, in model_from_chunks_async
obj = process_potential_object(
^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/tljh/anaconda3/envs/GEN_AI/lib/python3.12/site-packages/instructor/dsl/partial.py", line 108, in process_potential_object
return original_model.model_validate(parsed, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/tljh/anaconda3/envs/GEN_AI/lib/python3.12/site-packages/pydantic/main.py", line 716, in model_validate
return cls.__pydantic_validator__.validate_python(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
pydantic_core._pydantic_core.ValidationError: 1 validation error for Reasoning
chain_of_thought
Field required [type=missing, input_value={'penguins_csv': [{'speci...': 2001, 'count': 400}]}, input_type=dict]
Traceback (most recent call last):
File "/opt/tljh/anaconda3/envs/GEN_AI/lib/python3.12/site-packages/panel/io/server.py", line 158, in wrapped
return await func(*args, **kw)
^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/tljh/anaconda3/envs/GEN_AI/lib/python3.12/site-packages/panel/chat/feed.py", line 700, in _prepare_response
raise e
File "/opt/tljh/anaconda3/envs/GEN_AI/lib/python3.12/site-packages/panel/chat/feed.py", line 675, in _prepare_response
await asyncio.gather(
File "/opt/tljh/anaconda3/envs/GEN_AI/lib/python3.12/site-packages/panel/chat/feed.py", line 620, in _handle_callback
response = await self.callback(*callback_args, **callback_kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/tljh/anaconda3/envs/GEN_AI/lib/python3.12/site-packages/lumen/ai/utils.py", line 1071, in async_wrapper
return await func(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/tljh/anaconda3/envs/GEN_AI/lib/python3.12/site-packages/lumen/ai/ui.py", line 2367, in _chat_invoke
plan = await self._coordinator.respond(messages, exploration.context)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/tljh/anaconda3/envs/GEN_AI/lib/python3.12/site-packages/lumen/ai/utils.py", line 1071, in async_wrapper
return await func(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/tljh/anaconda3/envs/GEN_AI/lib/python3.12/site-packages/lumen/ai/coordinator/base.py", line 480, in respond
plan = await self._compute_plan(messages, context, agents, tools, pre_plan_output)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/tljh/anaconda3/envs/GEN_AI/lib/python3.12/site-packages/lumen/ai/coordinator/planner.py", line 540, in _compute_plan
raise e
File "/opt/tljh/anaconda3/envs/GEN_AI/lib/python3.12/site-packages/lumen/ai/coordinator/planner.py", line 520, in _compute_plan
raw_plan = await self._make_plan(
^^^^^^^^^^^^^^^^^^^^^^
File "/opt/tljh/anaconda3/envs/GEN_AI/lib/python3.12/site-packages/lumen/ai/utils.py", line 1071, in async_wrapper
return await func(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/tljh/anaconda3/envs/GEN_AI/lib/python3.12/site-packages/lumen/ai/coordinator/planner.py", line 342, in _make_plan
async for reasoning in self.llm.stream(
File "/opt/tljh/anaconda3/envs/GEN_AI/lib/python3.12/site-packages/lumen/ai/llm.py", line 438, in stream
async for chunk in chunks:
File "/opt/tljh/anaconda3/envs/GEN_AI/lib/python3.12/site-packages/instructor/dsl/partial.py", line 364, in from_streaming_response_async
async for item in cls.model_from_chunks_async(json_chunks, **kwargs):
File "/opt/tljh/anaconda3/envs/GEN_AI/lib/python3.12/site-packages/instructor/dsl/partial.py", line 493, in model_from_chunks_async
obj = process_potential_object(
^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/tljh/anaconda3/envs/GEN_AI/lib/python3.12/site-packages/instructor/dsl/partial.py", line 108, in process_potential_object
return original_model.model_validate(parsed, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/tljh/anaconda3/envs/GEN_AI/lib/python3.12/site-packages/pydantic/main.py", line 716, in model_validate
return cls.__pydantic_validator__.validate_python(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
pydantic_core._pydantic_core.ValidationError: 1 validation error for Reasoning
chain_of_thought
Field required [type=missing, input_value={'penguins_csv': [{'speci...': 2001, 'count': 400}]}, input_type=dict]
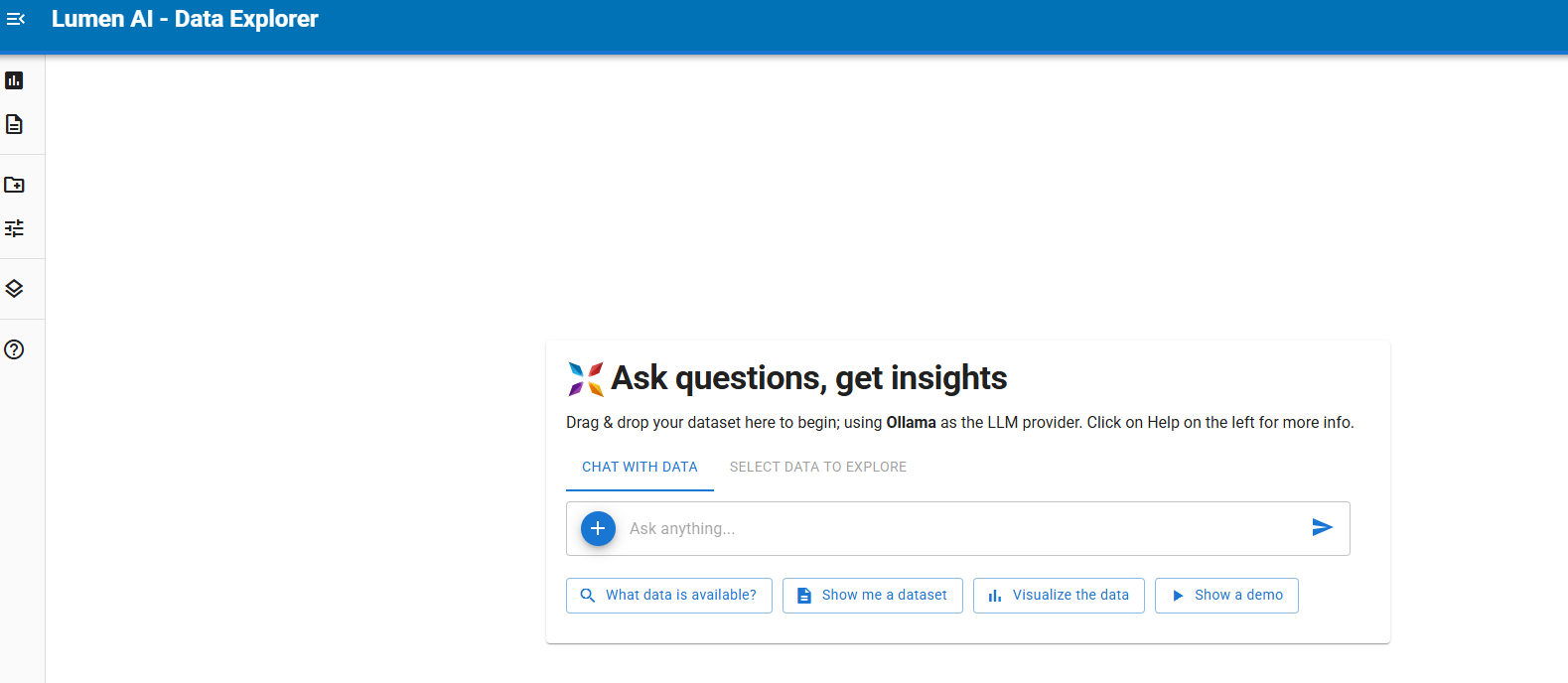
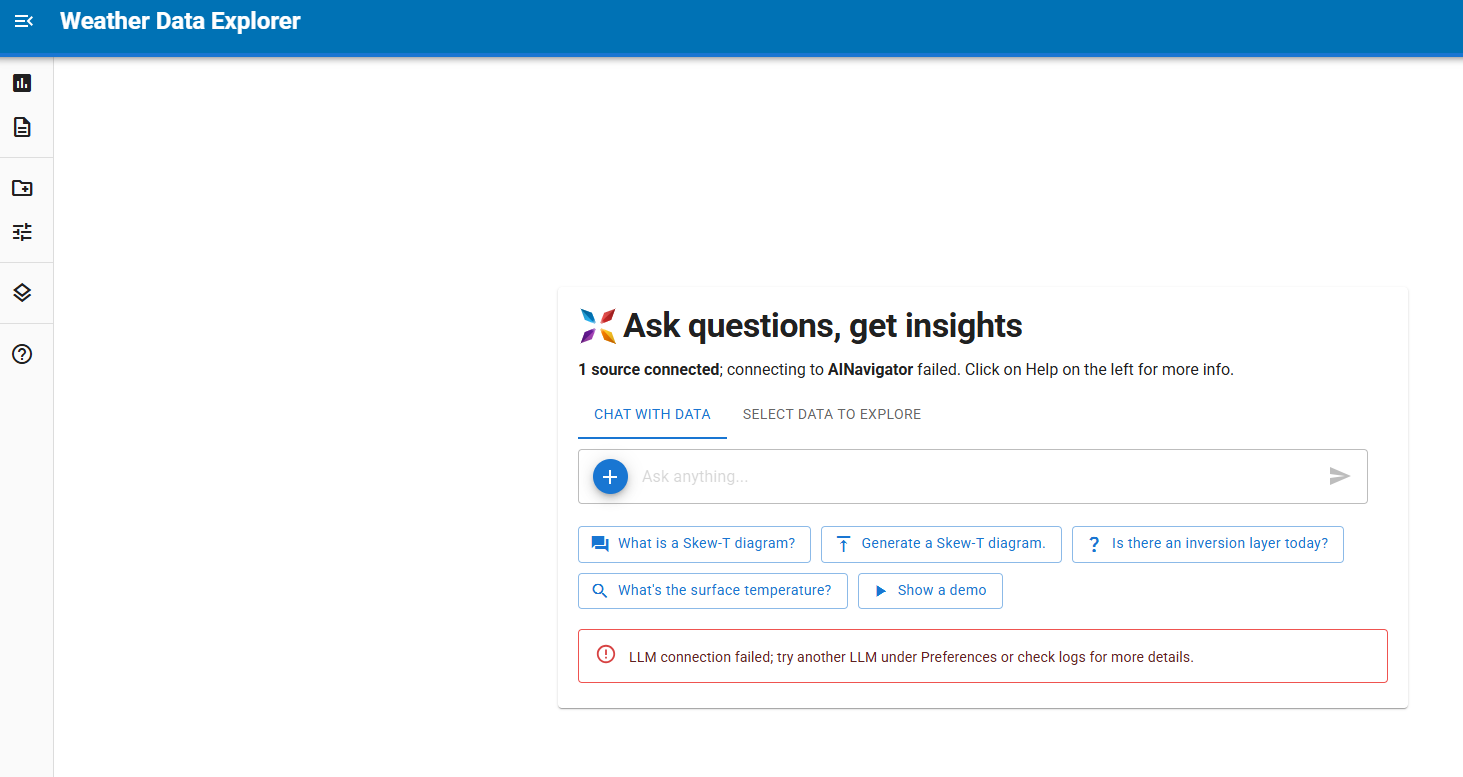
same thing if we just press show demo all prompt not working.