I am trying to draw two groups of scatterplots on one figure as in matplotlib two lines with scatter code. But the data is large and I need to view it interactively. I need to dynamically view some data properties using hover.
I am having trouble with this task. Here are the questions:
- How do I correctly display two or more groups of data on the same fig?
- How do I set specific colors for data for the user to recognize it? For example group 1 is red and group 2 is blue.
- How to add hover with displaying properties from dataframe for all DISPLAYED data?
- How to add the ability to turn off the display of selected dynamically groups?
I tried to implement orisovka taking “Multidimensional plots” as an example in the documentation
Working with large data using datashader
However, this example was not clear to me. I’m not sure if I need to use some functions like NdOverlay or dynspread. Also, I cannot figure out how to set specific colors for specific data. Perhaps this is what I need to do, and if this is so, then please show me exactly where I need to pay attention.
This applied to questions 1 and 2.
Here is the code with sample data and my attempt to solve the problem.
import pandas as pd
import random
import numpy as np
import holoviews as hv
import datashader as ds
from holoviews import opts
from holoviews.operation.datashader import datashade, dynspread
hv.extension('bokeh')
#Data can contain much more data and features
#Here, for example, only two data groups and one feature
N=int(10e5)
df = pd.DataFrame(np.random.randint(0,100,size=(N, 4)), columns=list(('x1','y1','x2','y2')))
df['feature']=np.random.random(N)
#This is where questions begin about how to do it correctly or fix the existing code
Data_1 = hv.Points((df['x1'],df['y1']),label="Data_1")
Data_2 = hv.Points((df['x2'],df['y2']),label="Data_2")
data_i_want_to_plot={'Data_1':Data_1,'Data_2':Data_2 }
c = dynspread(datashade(hv.NdOverlay(data_i_want_to_plot, kdims='k'), aggregator=ds.by('k', ds.count())))
c.opts(width=800, height=800).relabel('System')
Regarding questions 3 and 4, I have no idea how to do this at all, so please tell me how to do this. In the example above, this possibility should already be taken into account in the future.
Thanks in advance!
I made some progress in solving this problem, but there were problems. Sample code below.
from bokeh.models import HoverTool
import pandas as pd
import random
import numpy as np
import holoviews as hv
import datashader as ds
from holoviews.operation.datashader import datashade, shade, dynspread, spread, rasterize
import colorcet
hv.extension('bokeh','matplotlib')
N=int(10e4)
df = pd.DataFrame(np.random.randint(0,100,size=(N, 4)), columns=list(('x1','y1','x2','y2')))
df['feature']=np.random.random(N)
s=hv.Points( df,['x1','y1'], ['feature'],label='s')
r=hv.Points( df,['x2','y2'], ['feature'],label='r')
S_cord=rasterize(s).opts(cmap=colorcet.kr)
R_cord=rasterize(r).opts(cmap=colorcet.kb)
tooltips = [
('feature', '@feature')
]
hover = HoverTool(tooltips=tooltips)
((S_cord).opts( tools=[hover])*R_cord.opts(tools=[hover])).opts(height=500, width=500)
The new version of the code is above. The following questions arose.
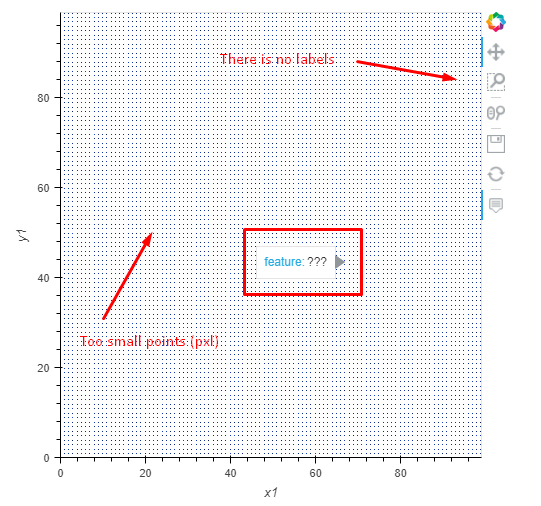
- Why are the final points (pixels) so small?
- I read “Setting options” in the Working with large data using datashader, which said that this is solved using
spread but I ran into the following error ```TypeError: Expected Image , got: `<class ‘xarray.core.dataarray.DataArray’>````
- What’s wrong with the Hover? It doesn’t show anything.
- There are no labels here. Although I enter them and use the
* operator
- In the course of work, it became interesting if, when choosing a point, it is possible to automatically read and write a predetermined header value into a buffer?
The idea is as follows. The user finds the required point or object and selects it. Next, a specific header is read from the selected point (it will be displayed in the hover). And after all this, the read value will be fed into another program - that is, you just need to read this property. In the example program above, this is actually the feature variable.
- spread and dynspread can indeed help you make those pixels visible. Until recent versions of Datashader, spreading was supported only on RGB images, specifically the output of
datashade(), but recent versions now support the numerical array output of rasterize() as well. The error message indicates that you are using an outdated version of Datashader; update with conda install -c pyviz datashader.
- Here you’ve enabled hover for the column “feature”, but the rasterized data doesn’t have any such column, and indeed, has no columns at all; it is an image and not a columnar data source. The original data has such a column, sure, but you’ve used Datashader to count the datapoints per pixel and displayed those counts, and what Bokeh sees is now a rasterized hv.Image plot with no other information from the original dataset. Read more at datashader.org to see how that works and why you can no longer access anything from the original dataset. If you want to display the “feature” column in hover, you can aggregate by “feature”, displaying e.g. the average value of “feature” per pixel rather than the counts per pixel; see the
aggregator argument to rasterize. That way Datashader will compute the value of feature per pixel, rather than the count of datapoints per pixel.
- You mean a legend? Sorry; I misled you before; you’ll only get a legend here if you overlay points, not rasterized points. Bokeh does automatically create a legend for overlaid points plots, but these are now overlaid image plots, and it doesn’t currently create the legend in that case. See the Large Data guide about how to fake a legend, which is unfortunately all we support right now.
- I’m not sure what you mean, but I think that can be done with the new
inspect_points feature in HoloViews. See https://examples.pyviz.org/ship_traffic/ship_traffic.html for an example where one selects a point and then it shows a table about that point and a photo corresponding to that point. The example is a bit complicated due to its use of geographic tools, but I’m working to simplify it. I believe you can already use it as you are describing, though.
Here’s an example with some of the fixes discussed above, but note that it doesn’t work to overlay these two plots right now because they overlap entirely, as all the datapoints fall on integer locations. If your actual data is the same way, you’ll need to rearrange it to have a categorical column (e.g. “S” or “R” for each datapoint) and then use Datashader’s categorical plotting support, or else you’ll never see the S datapoints, as they are always covered up by the R datapoints. But I hope that’s not your situation, because the categorical plotting can’t be used together with hover. The categorical support does work with inspect_points, though, as that doesn’t care how you are plotting it.
import random, pandas as pd, numpy as np, holoviews as hv, datashader as ds, colorcet as cc
from holoviews.operation.datashader import datashade, shade, dynspread, spread, rasterize
hv.extension('bokeh')
N=int(10e4)
df = pd.DataFrame(np.random.randint(0,100,size=(N, 4)), columns=list(('x1','y1','x2','y2')))
df['feature']=np.random.random(N)
s=hv.Points( df,['x1','y1'], ['feature'],label='s')
r=hv.Points( df,['x2','y2'], ['feature'],label='r')
S_cord=dynspread(rasterize(s, aggregator=ds.mean("feature")).opts(cmap=cc.kr))
R_cord=dynspread(rasterize(r, aggregator=ds.mean("feature")).opts(cmap=cc.kb))
S_cord*R_cord.opts(tools=["hover"]).opts(height=500, width=500)
1 Like