When referencing sample pdf on local disk works fine. If i try to reference a larger one page pdf, nothing renders in panel…
Hi @andre
Welcome to the community.
Please post a minimum reproducible, code example. It will help the community to focus on the right issue and Solution. Thanks ![]()
import panel as pn
import os
pdf_pane = pn.pane.PDF(object=None, embed=True)
pdf_pane.object = os.path.join(os.path.dirname(file), “data”, “example.pdf”)
pdf_pane.show()
#the sample pdf works fine, maybe cause of its small size. but using a real world single page pdf does not render.
__file __
1 Like
Hi @Andre . Could you upload a specific pdf that does not render? Thanks.
Confidentiality issues with the pdf contents. Is there maybe a file size limit? Small pdf maps <2mb works. But if pdf map has imagery and file size around 5mb doesnt work.
Maybe time to give up on pdf panel and try pdf.js Would it be easy to integrate into panel?
Just a thought, maybe local development and local host limits what size pdf I can render?
1 Like
Hi @Andre,
It might be worth checking you have the tornado server set to accept max message size, this thread has something about it but I’m sure I’ve saw @Marc put some details together neatly somewhere. Maybe nothing to do with your issue but worth a try seeing it seems like file size problems but 5mb seems low so maybe another issue entirely…
https://discourse.holoviz.org/t/panel-fileinput-not-updating-param-parameter-value/3184
1 Like
I tried with 2 files, 1 of 2 MB and it works ok, the second of 35MB does not render for me in chrome and windows.
import panel as pn
pdf_pane = pn.pane.PDF('reservoir.pdf')
pn.Row(pdf_pane).servable()
I think the tornado limit is around 100 MB.
2 Likes
I experience the same on ubuntu firefox, I do have to add a height/width value for any pdf to work and embed =True. Strangely I did get the reservoir pdf to render but in error and unrepeatable, I say strangely because I could see the whole jupyter lab rendered within the notebook itself and within the jupyter lab in the notebook was the reservoir pdf loaded and could scroll the pages. I have no idea, I’ve tried to repeat but seemed a one off thing.
Great ! thanks for checking. I tried with chrome, firefox, and a new environment and it keeps not rendering, in windows and panel 0.13.0.
I tried with
panel serve --show --autoreload pdf.py --websocket-max-message-size=90000000
because the pdf is converted to base64 encoding. Then the file pass from 35 MB to 49MB, but it works neither.
It seems to work well if you provide a full web path ie https,
#works 100MB PDF
import panel as pn
pn.extension()
pdf_pane = pn.pane.PDF('https://cartographicperspectives.org/index.php/journal/article/view/cp43-complete-issue/pdf',embed=True,height=1000,width=800)
pdf_pane.servable()
The above seems to work consistently - I’ve restarted my server etc and works with latest panel on my system. The more I play off of the full web path I get strange behaviour now instead of displaying the sample pdf if I use .show() like below in notebook it lets me know there is a tornado access error.
What I’m not following is initially I was getting same behaviour as previous posts, now though I can’t display a small file with .show() either, I consistently get the access error. Maybe this is part of the issue of what is going on at least on my system.
So for me unless the full ‘web’ path is provided it won’t work properly, for local files I’d either have to set up an ftp I think or do the below by @nghenzi2019
#same 100MB file on local storage does not work
import panel as pn
pn.extension()
pdf_pane = pn.pane.PDF('cp43-complete-issue.pdf',embed=False,height=1000,width=800)
pdf_pane.show()
Thanks, Carl.
I found this, it seems there is some problem with base64 embedded in the browser
Following the instruction there and embedding the content in an iFrame it was possible for me to render the pdf. It is a really hacky and not a good solution, but it works…
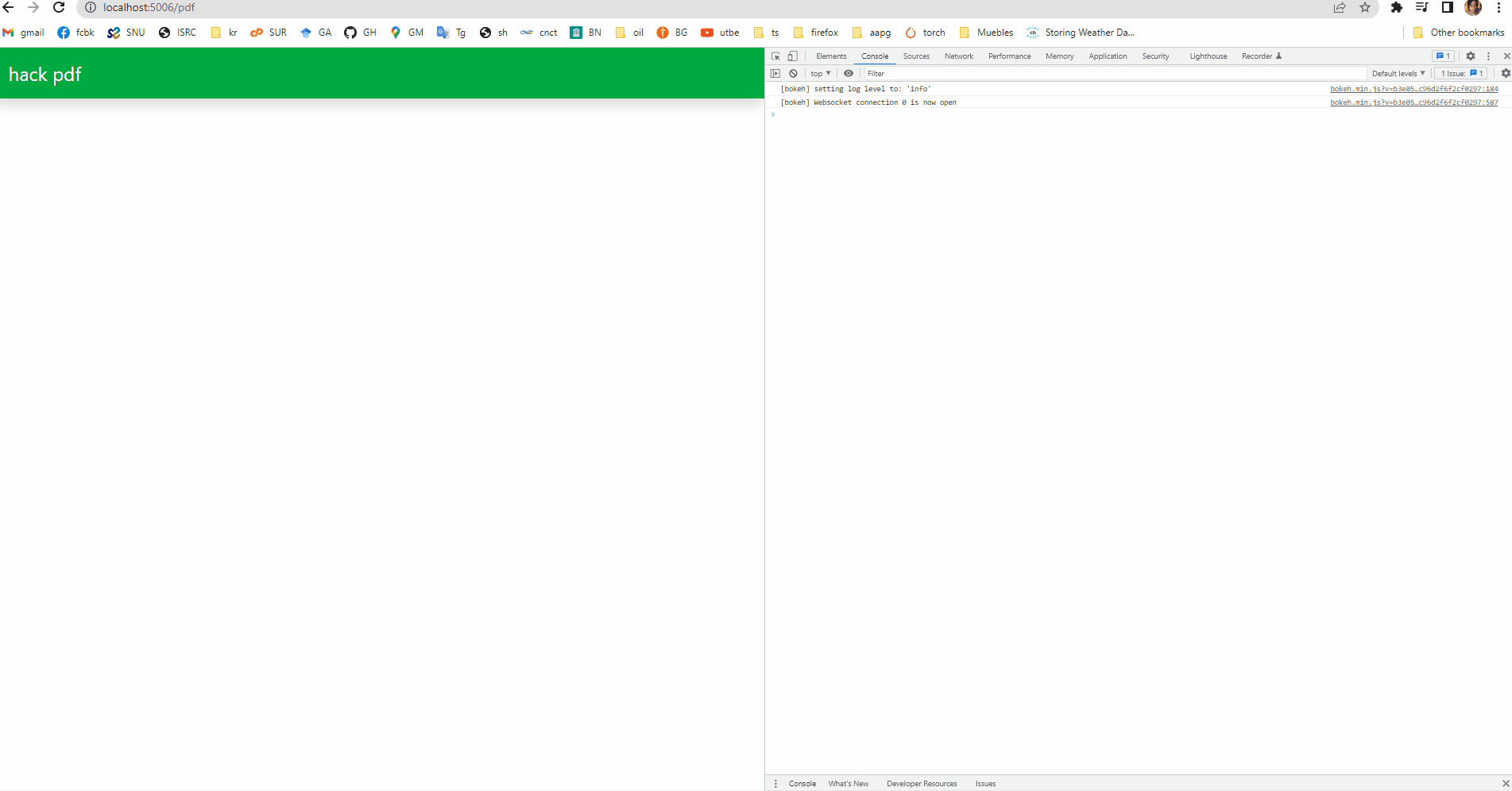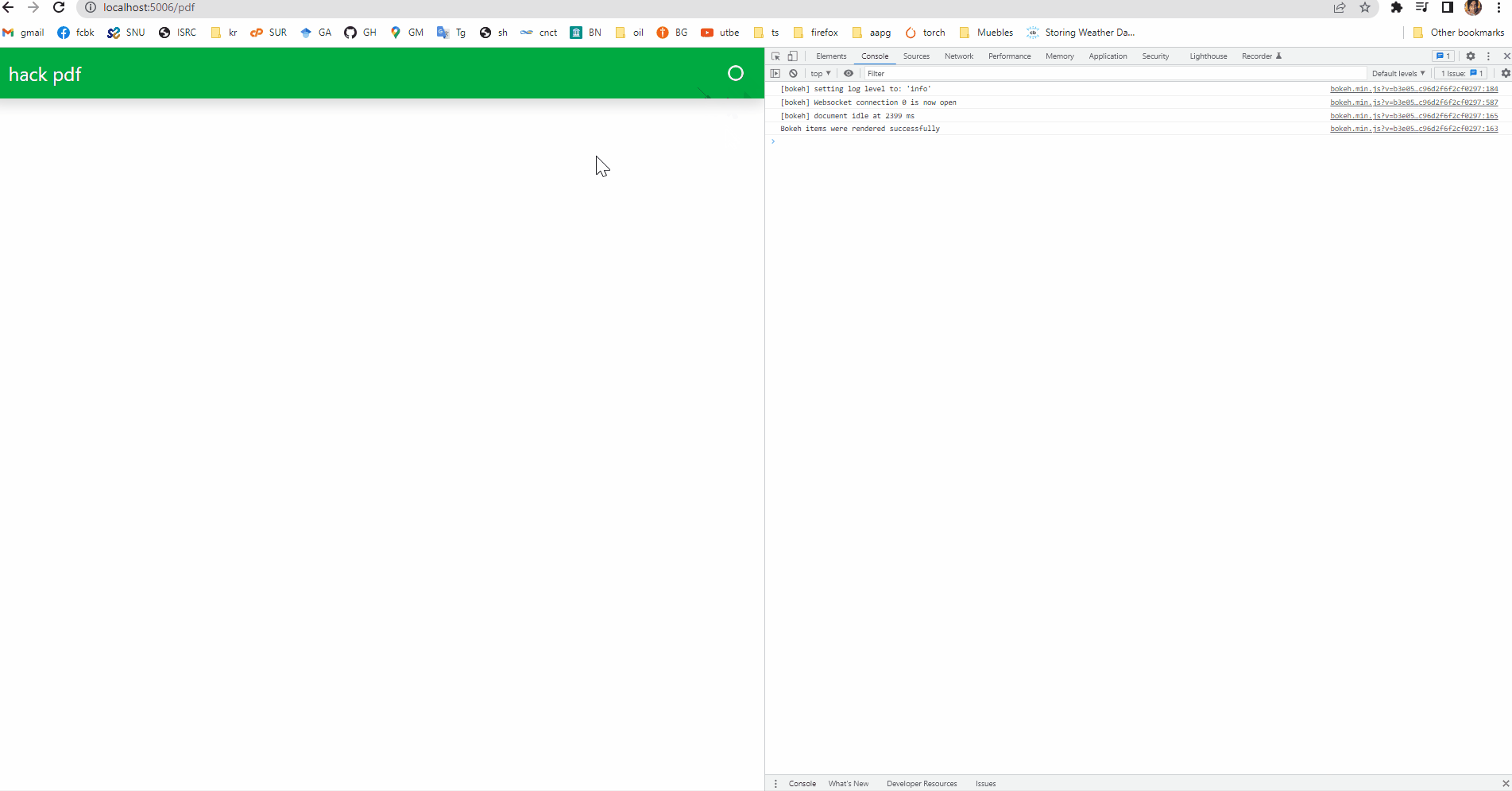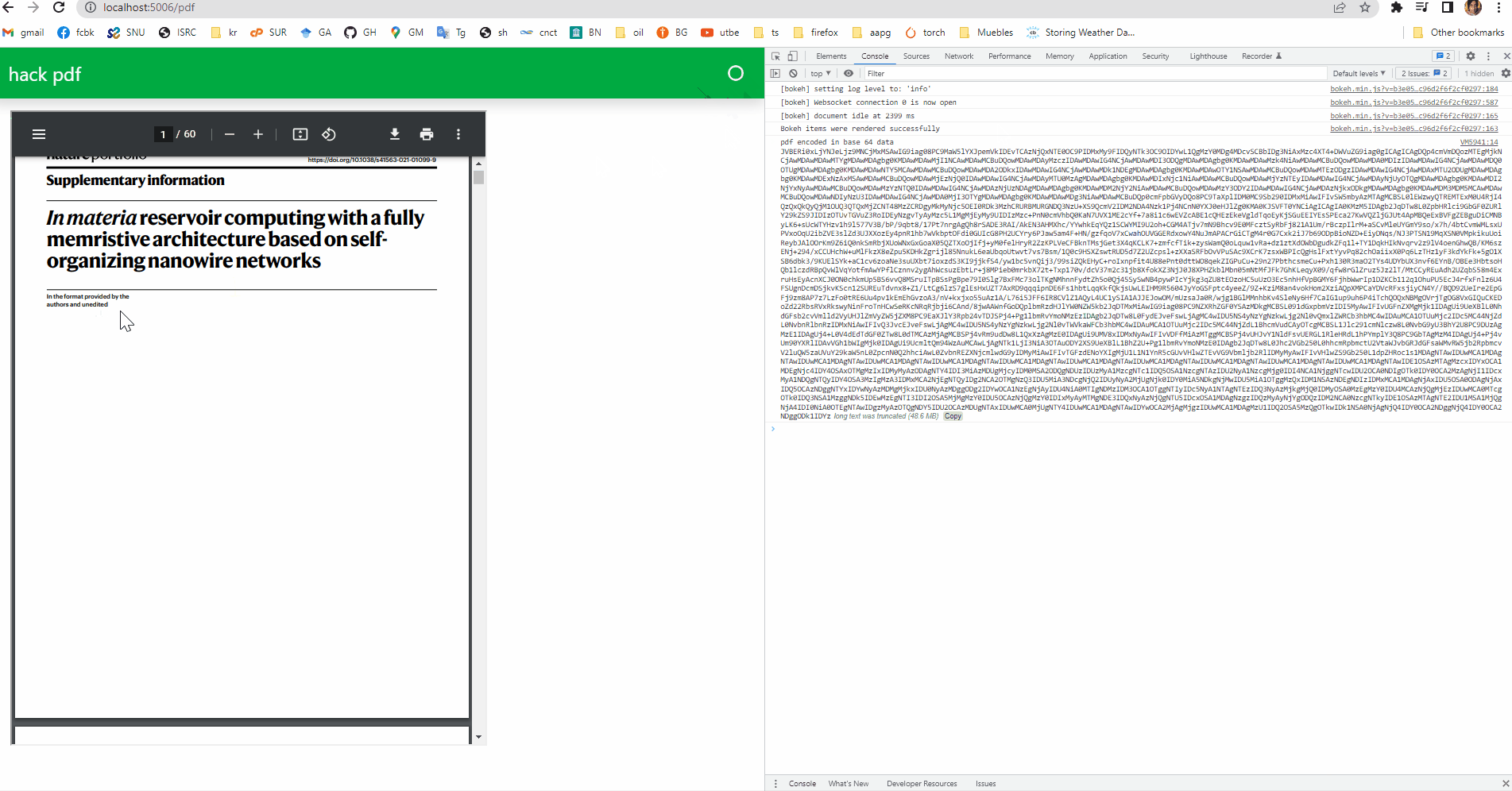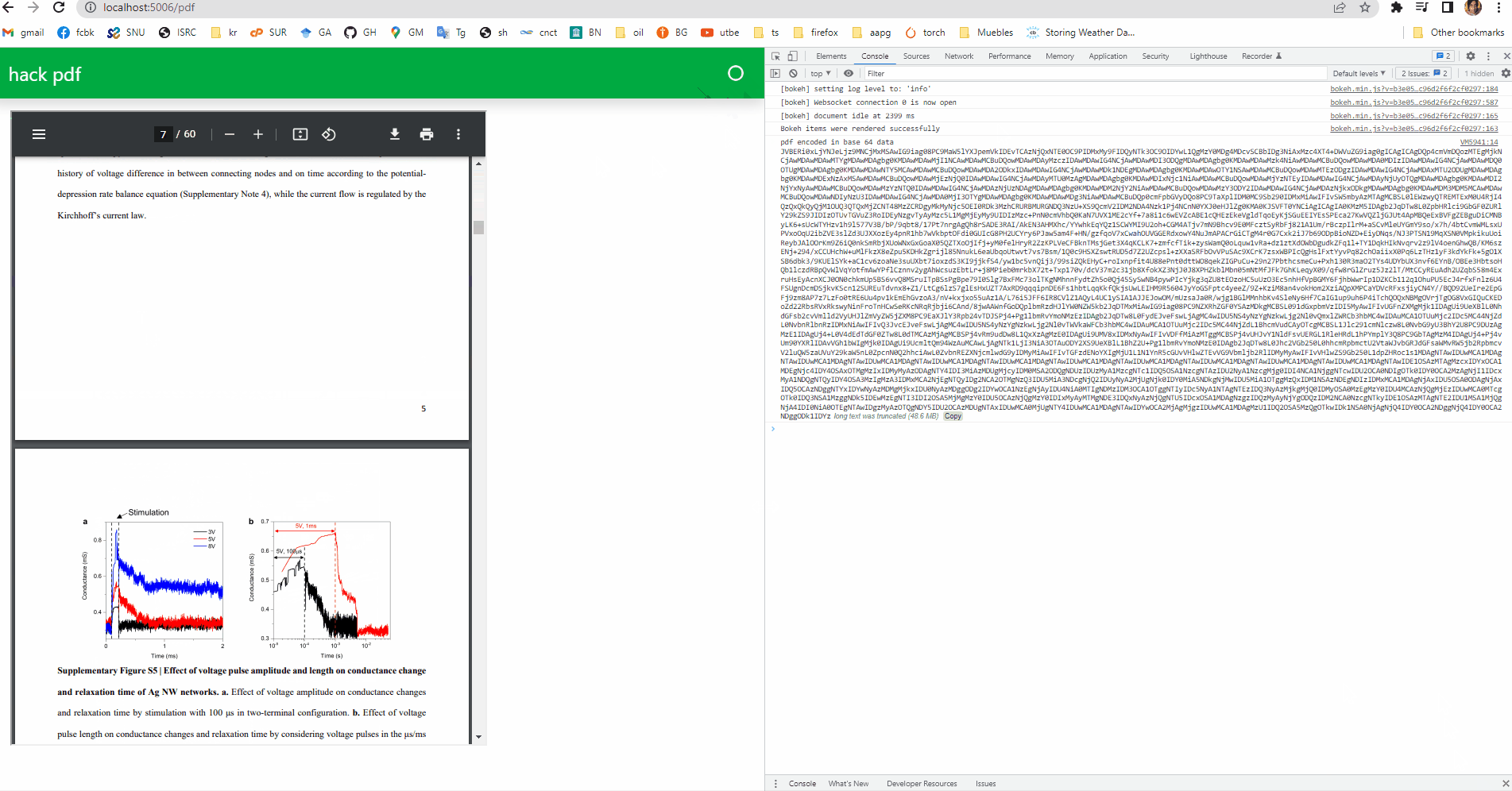
import panel as pn
pdf_pane = pn.pane.PDF('reservoir.pdf',
height = 0, width = 0, embed=True, css_classes =['pdf_reser'])
html = pn.pane.HTML(""" <div id='pdf_frame' style="height: 800px; width:600px; "> <div>
<script>
function docReady(fn) {
// see if DOM is already available
if (document.readyState === "complete" || document.readyState === "interactive") {
// call on next available tick
setTimeout(fn, 1);
} else {
document.addEventListener("DOMContentLoaded", fn);
}
}
docReady(function() {
const pdf_data = document.getElementsByClassName('pdf_reser')[0].firstElementChild.firstElementChild.src.split(',')[1]
console.log('pdf encoded in base 64 data ',pdf_data)
var b64Data = pdf_data;
var contentType = "application/pdf";
const blob = b64toBlob(b64Data, contentType);
var iFrame = document.createElement("iframe");
iFrame.setAttribute('height', '800px')
iFrame.setAttribute('width', '600px')
iFrame.src = URL.createObjectURL(blob);
document.getElementById('pdf_frame').appendChild(iFrame);
});
const b64toBlob = (b64Data, contentType = '', sliceSize = 512) => {
const byteCharacters = atob(b64Data);
const byteArrays = [];
for (let offset = 0; offset < byteCharacters.length; offset += sliceSize)
{
const slice = byteCharacters.slice(offset, offset + sliceSize);
const byteNumbers = new Array(slice.length);
for (let i = 0; i < slice.length; i++) {
byteNumbers[i] = slice.charCodeAt(i);
}
const byteArray = new Uint8Array(byteNumbers);
byteArrays.push(byteArray);
}
const blob = new Blob(byteArrays, { type: contentType });
return blob;
}
</script>""",width=600, height=800)
tmpl = pn.template.BootstrapTemplate(title='hack pdf')
row = pn.Row(pdf_pane, html, sizing_mode='stretch_both')
tmpl.main.append(row)
tmpl.servable()
2 Likes