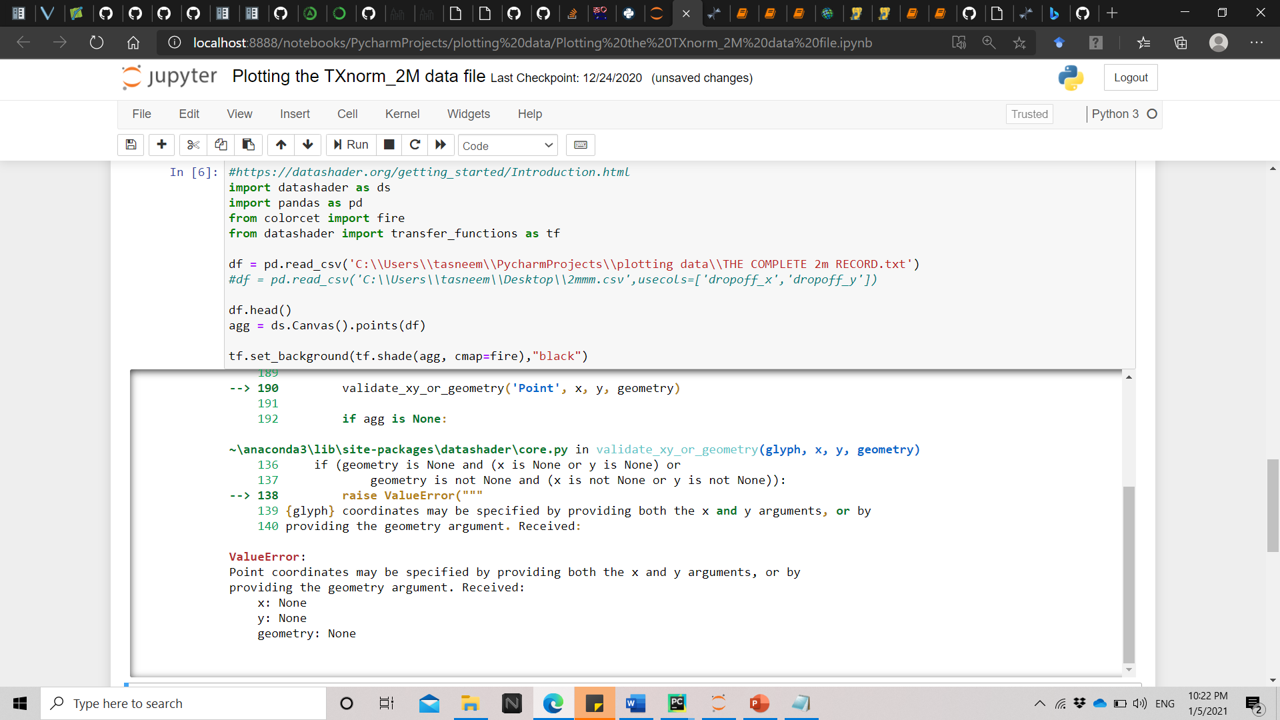
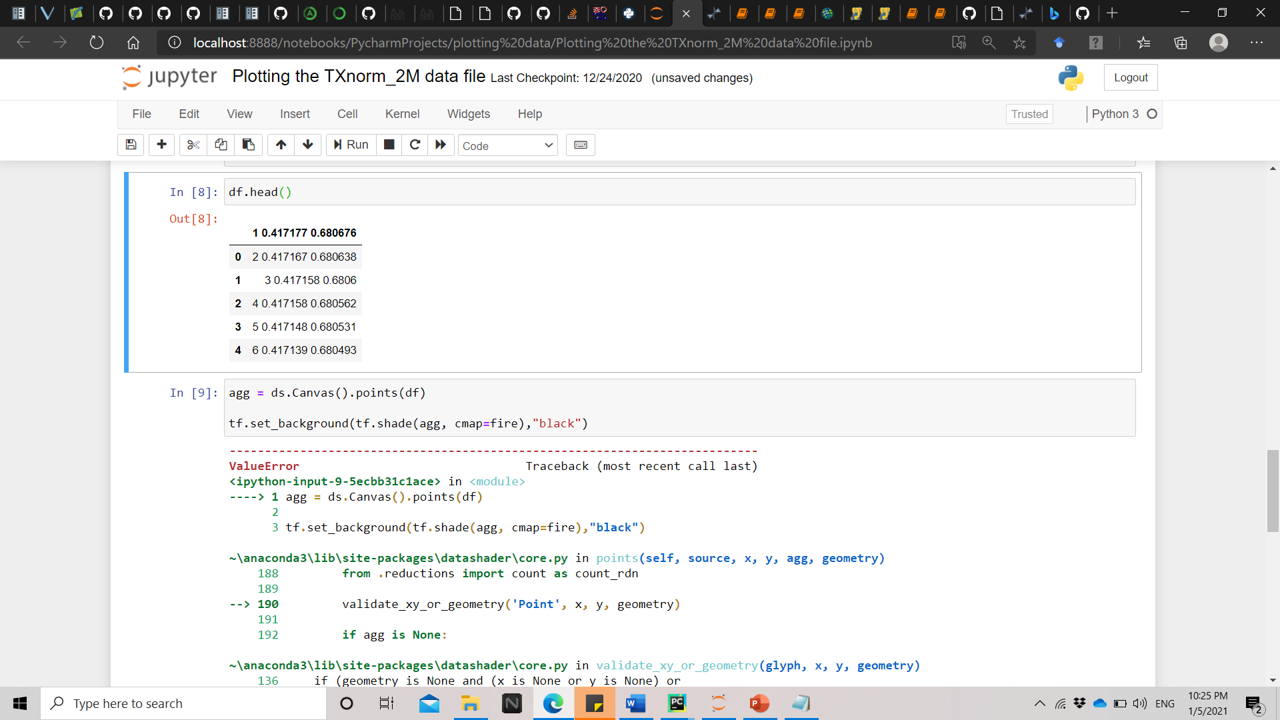
I am trying to draw a road network consisting of 2 million records.
Is there a way to read this data from a txt file, because the maximum numbers of rows that can fit into a csv file is 1048576
Tried this before and searched for a function that reads a txt.
I think that this function should be changed pd.read_csv( )
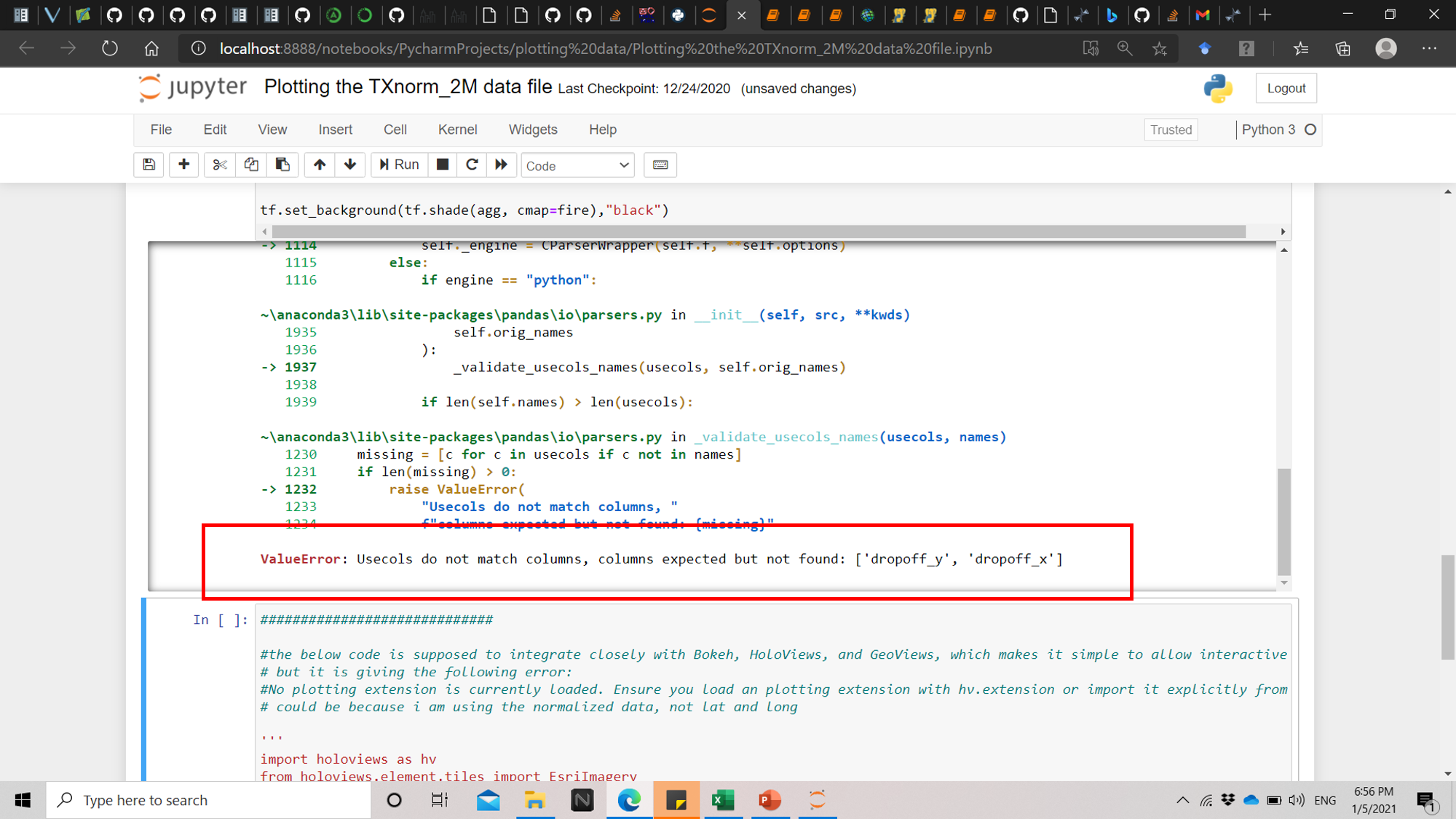
because when I try to replace with .txt it gives an error that the column names are missing while they are not.
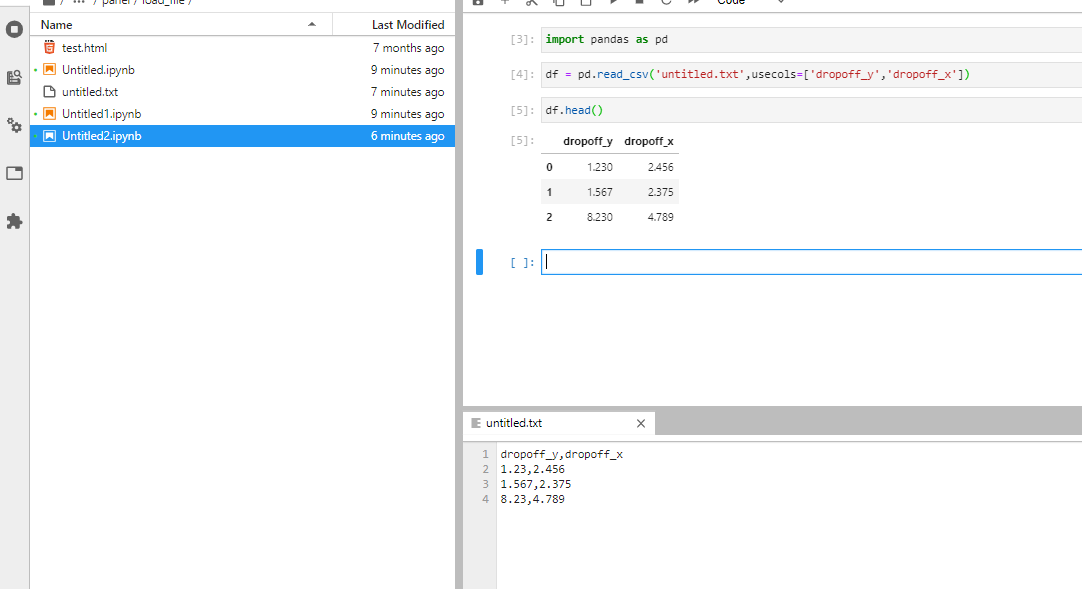
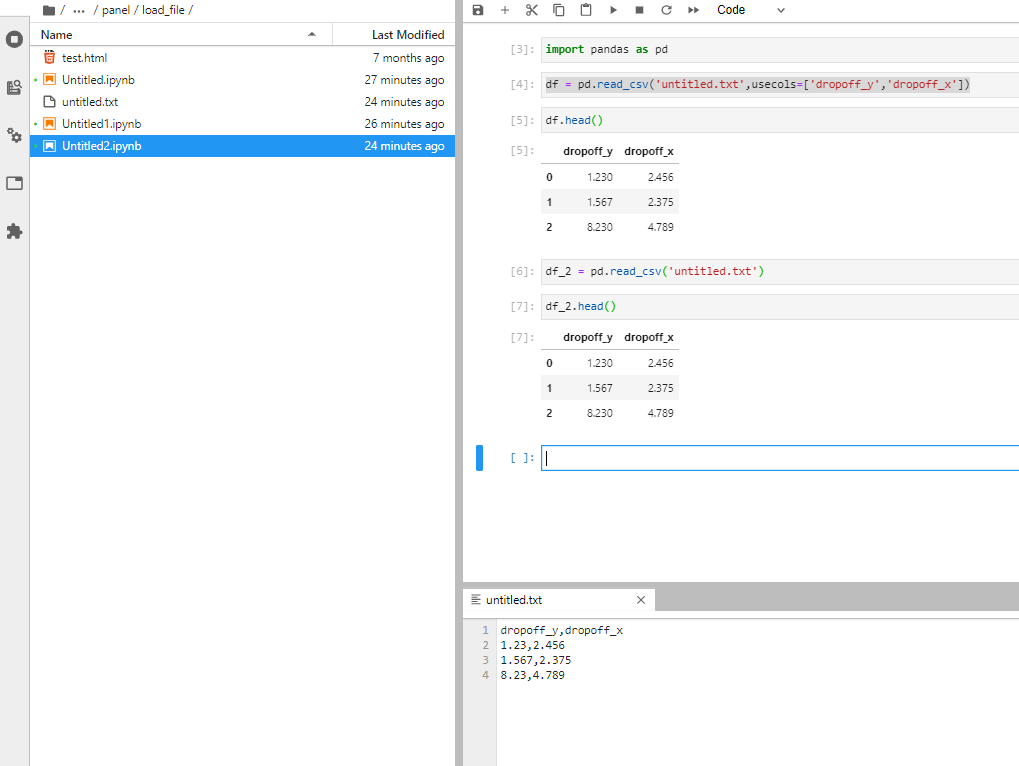
I suspect but I don’t know, the file you might be loading maybe doesn’t actually have headers try without usecols and see what you get… if I do the following it loads into the dataframe
What you show is an Excel row limit. It has nothing to do with csv.
How to create the .csv file depends on where your data is coming from. If it is data you calculate, then you can use python (and potentially pandas) to create and save it.
I would need to know more details on your use case to know how it can be solved.
Actually it is a ready-made spatial dataset of a road network (normalized latitude and longitude values) saved as a txt file.
It is similar to the concept of Openstreet map that generates a dataset of a geographical area that you specify.
My problem lies in using datasher to draw the dataset as an image. So I am compelled to use agg = ds.Canvas().points(df,‘dropoff_x’,‘dropoff_y’) to draw the points and this function has 3 attributes that I have to specify: dataframe, x coordinate, y coordinate
Just one more thing not seeing the file your working with it also appears like you might need to supply an appropriate separator in the read function something like sep=‘ ‘ for a space it looks like pandas thought you had one column when it looks like there is three, an index and your x,y columns.