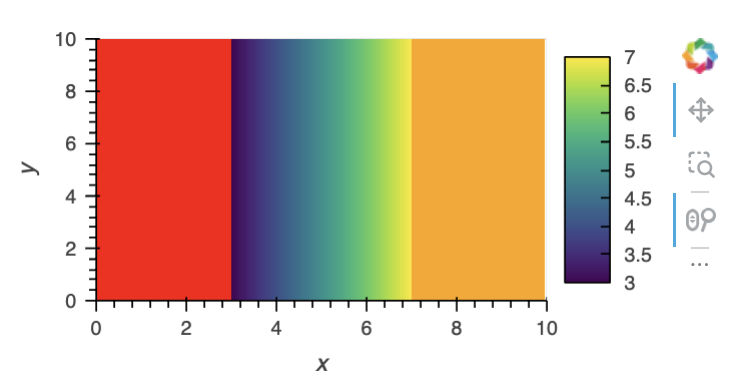
" So, I’m trying to render some points, coloring them by a continuous variable, say with values between 0 and 10. Currently, I’m using the span argument of shade() to restrict the value range that should be shown to e.g. [3, 7]. I pass a Colormap to the cmap argument. If I understand correctly, datashader always treats values below 3 as if they were 3 and values above 7 as if they were 7, so they get the lowest/highest value in the colormap. Ideally, there would be a way for me to get a behavior similar to matplotlib’s clip argument of Normalize when set to False : I would like the values outside of span to be colored using the under and over value of the Colormap that I pass and not always get a result as if clip=True . Do you know if there’s already some way to get that behavior?"
I think the span parameter in shade() will always clamp values to the ends of the colormap range. So I think the best approach is to use rasterize to allow Bokeh to handle the colormapping, and then set the backend opts with HoloViews (with Bokeh backend) to specify the low and high colors like this:
import numpy as np
import pandas as pd
import holoviews as hv
import datashader as ds
from holoviews.operation.datashader import rasterize
hv.extension('bokeh')
N = 500
low_thresh = 3
high_thresh = 7
xs = np.linspace(0, 10, N)
ys = np.linspace(0, 10, N)
X, Y = np.meshgrid(xs, ys)
val = X.ravel()
df = pd.DataFrame({
'x': X.ravel(),
'y': Y.ravel(),
'val': val,
})
points = hv.Points(df, kdims=['x', 'y'], vdims=['val'])
raster = rasterize(
points,
aggregator=ds.mean('val'),
)
raster = raster.opts(
width=400,
height=200,
cmap='Viridis',
clim=(low_thresh, high_thresh),
colorbar=True,
tools=['hover'],
backend_opts={
'glyph.color_mapper.low_color': 'red', # color for < low_thresh
'glyph.color_mapper.high_color': 'orange', # color for > high_thresh
}
)
raster
Yes, I think that would address my issue. Thanks a lot! Currently, we only use datashader and not holoviews, so the code would need a lot of refactoring. But if we switch to holoviews for interactive rendering at some point, I think we would get it to work.
Maybe @jbednar or @philippjfr can chime in if there’s a less cumbersome approach, but you could avoid HoloViews and Bokeh altogether by filtering the highs and lows out and stacking the resulting images.
Yeah, that’s the approach I’d take if I couldn’t use Bokeh. That code could be wrapped up into a transfer function so that it could easily be added to the end of a Datashading pipeline. Then if you are happy with it, you could submit it for inclusion in Datashadet!
Thanks a lot for the Boke-free version! I included it in our codebase and have a working version now, which is really cool Had to do a little adaptation, because downstream, I would like to use final_img.to_numpy().base to get the rgba array. Not sure why, but this only works for Images you get from tf.shade() and not from tf.stack(). That’s why I “manually” stack the three arrays I get from img_in.to_numpy().base and so on. Maybe someone knows if there is a more elegant version that works the same way.
Apart from that, does anyone have a rough idea how badly splitting the shading into 3 parts affects runtime and memory? We mostly included datashader to have a fast plotting backend alternative for very large datasets…
Yea, I personally think it’s fine to manually np.concatenate the X.to_numpy().base arrays. It’s only three arrays and it makes the operation explicit.
As for the runtime and memory impact of splitting shading into three parts, I’m guessing that it can affect performance, but probably by a consistent amount; the number of computationally expensive operations are the same. I’d suggest profiling your code with actual data of different sizes to accurately assess the impact.