I got inspired and made the version below.
I found that langchain also provides a async apredict method that helps make your Panel app performant/ non-blocking.
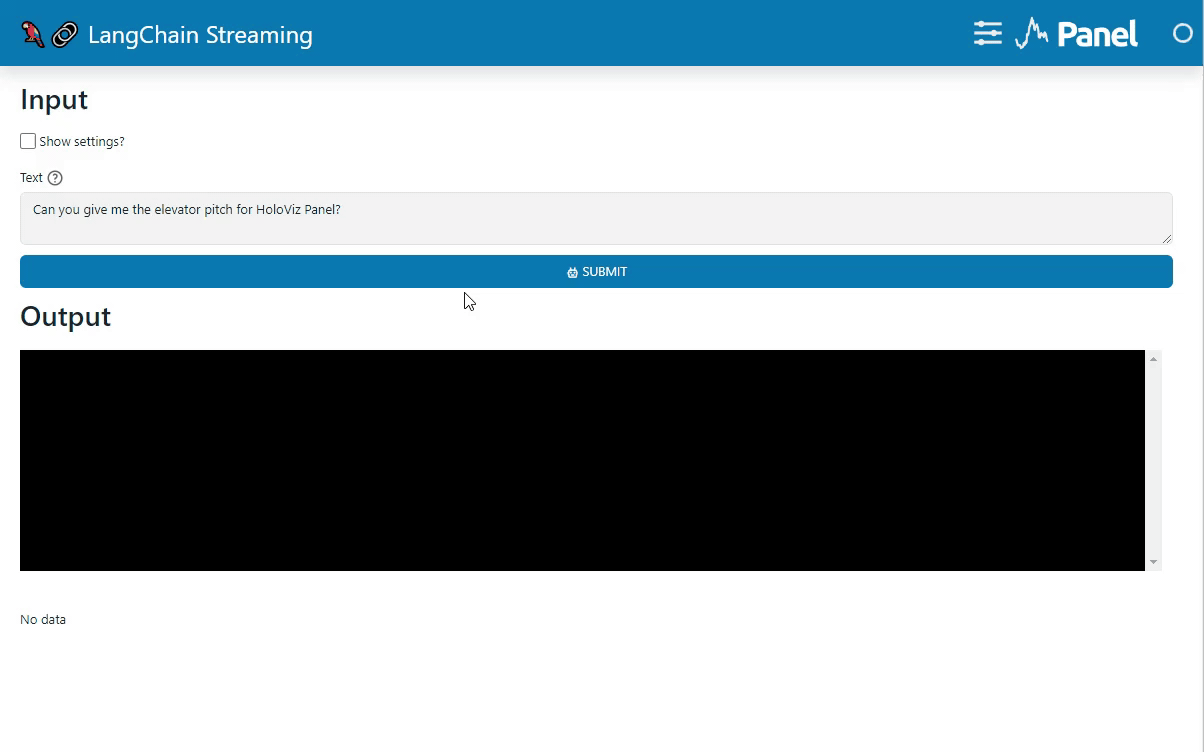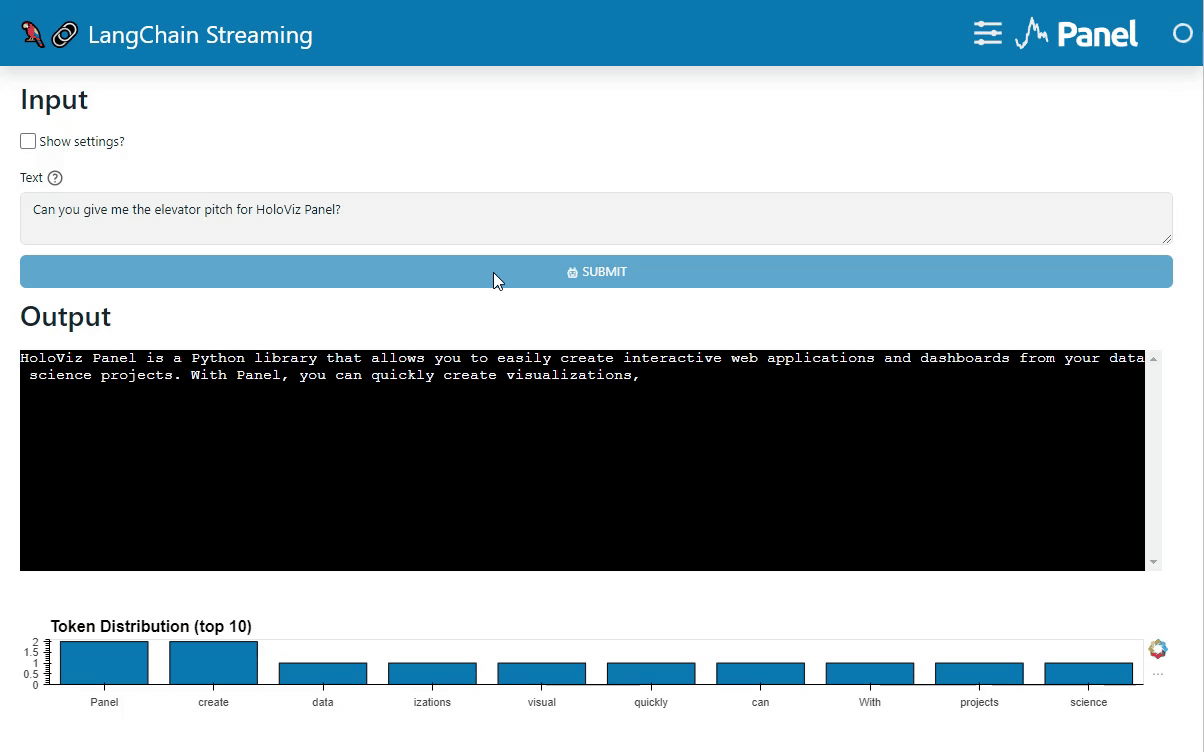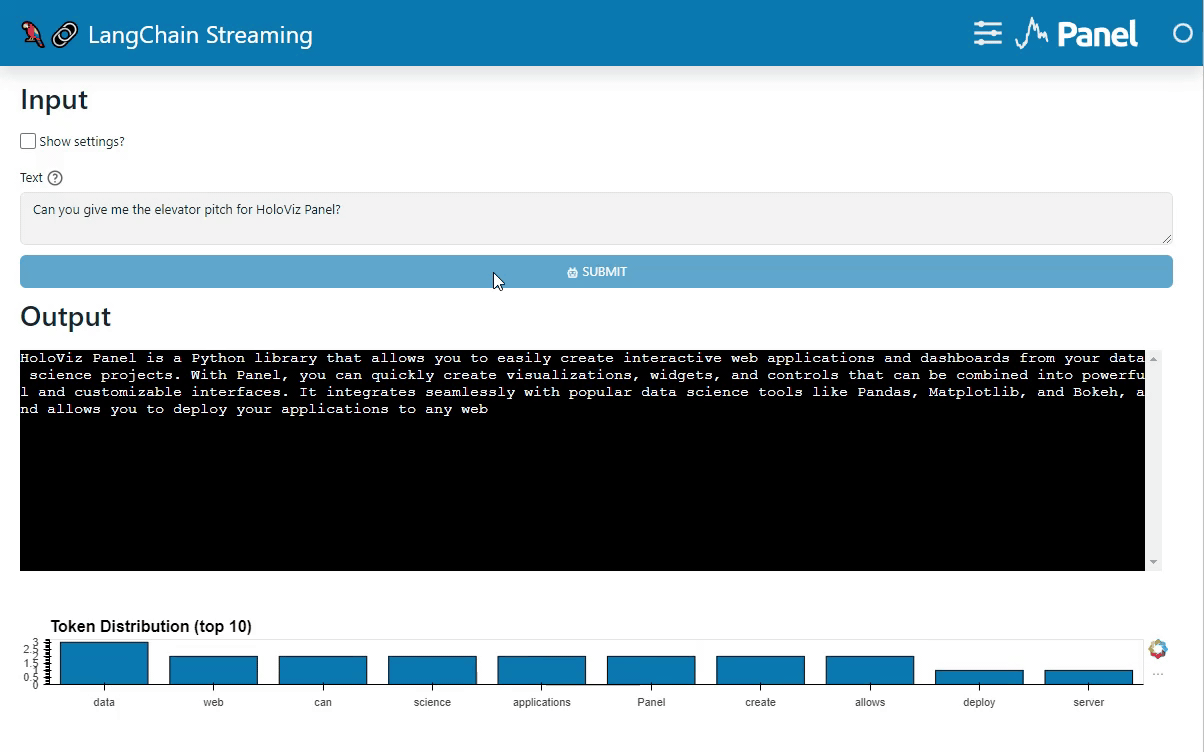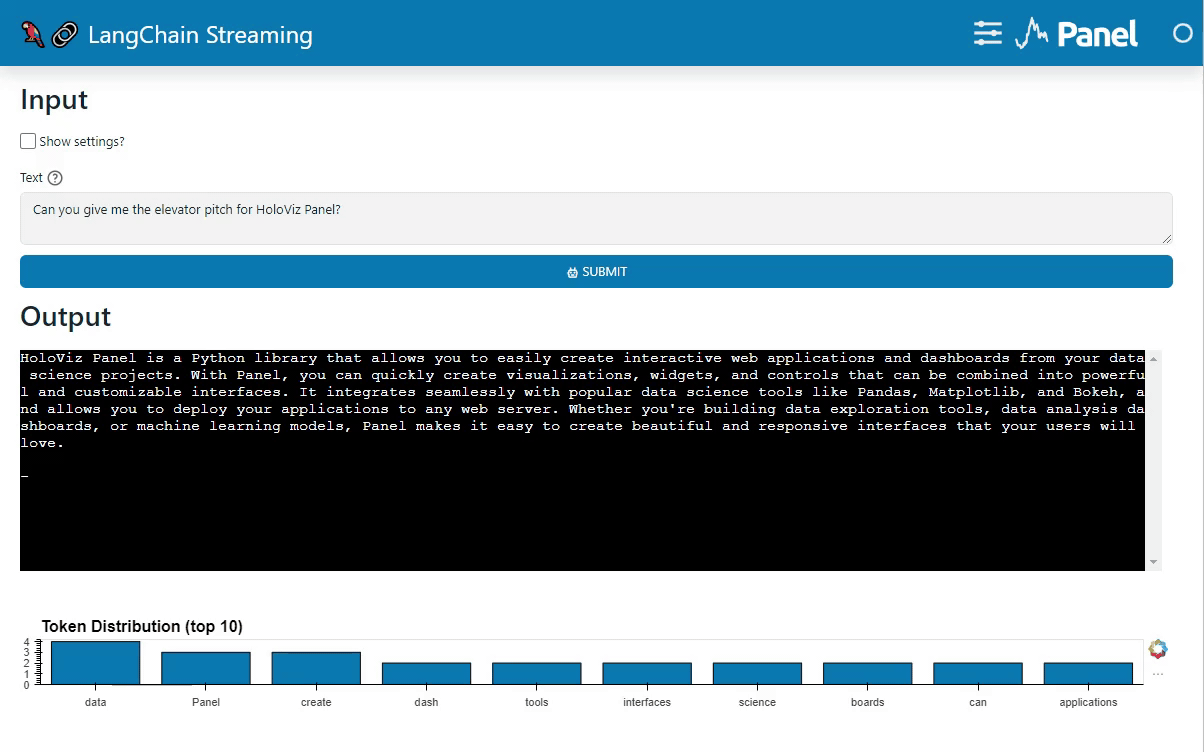
I used the Terminal widget because it can stream (.write) the tokens incrementally. With the TextInput or TextInputArea you will have to send the concatenated tokens for each new token, which is not really efficient.
import panel as pn
from langchain.callbacks.base import BaseCallbackHandler
from langchain.chat_models import ChatOpenAI
import param
import hvplot.pandas
import pandas as pd
pn.extension("terminal", sizing_mode="stretch_width", design="bootstrap")
text = pn.widgets.TextAreaInput(value="Hello, how are you?", name="Text")
class ChatStreamCallbackHandler(BaseCallbackHandler):
"""A basic Call Back Handler that will update the token on the chat widget provided"""
def __init__(self, chat: "ChatWidget"):
self.chat = chat
def on_llm_new_token(self, token: str, **kwargs) -> None:
self.chat.token = token
class ChatWidget(pn.viewable.Viewer):
text: str = param.String(
default="Can you give me the elevator pitch for HoloViz Panel?",
doc="""The text to submit to the chat api""",
)
submit: bool = param.Event(label="SUBMIT")
token: str = param.String(doc="""The single token streamed from the chat api""")
value: str = param.String()
is_predicting: bool = param.Boolean(
default=False, doc="""True while the chat is predicting"""
)
max_tokens = param.Integer(
default=250,
bounds=(1, 2000),
doc="""The maximum number of tokens returned by the chat api""",
)
streaming = param.Boolean(
default=True, doc="""Whether or not to stream the tokens"""
)
def __init__(self, **params):
super().__init__(**params)
self._create_panel()
self._create_chat()
def __panel__(self):
return self._panel
def _create_panel(self):
self._terminal = pn.widgets.Terminal(height=250)
pn.bind(self._terminal.write, self.param.token, watch=True)
self._submit_button = pn.widgets.Button.from_param(
self.param.submit, button_type="primary", icon="robot"
)
self._text_input = pn.widgets.TextAreaInput.from_param(self.param.text)
self._show_settings = pn.widgets.Checkbox(value=False, name="Show settings?")
self._settings = pn.Column(
self.param.max_tokens,
visible=self._show_settings,
)
self._panel = pn.Column(
"### Input",
self._show_settings,
self._settings,
self._text_input,
self._submit_button,
"### Output",
self._terminal,
)
@pn.depends("max_tokens", "streaming", watch=True)
def _create_chat(self):
stream_handler = ChatStreamCallbackHandler(chat=self)
self._chat = ChatOpenAI(
max_tokens=self.max_tokens,
streaming=self.streaming,
callbacks=[stream_handler],
)
@pn.depends("is_predicting", watch=True)
def _handle_predicting(self):
self.param.submit.constant = self.is_predicting
@pn.depends("submit", watch=True)
async def apredict(self):
self.is_predicting = True
self.value = await self._chat.apredict(self.text)
self.is_predicting = False
if self._terminal:
self._terminal.writelines(lines=["\n\n", "-", "\n\n"])
token_map = {}
chat = ChatWidget()
STOP_WORDS = {
"",
"a",
"about",
"above",
"after",
"again",
"against",
"all",
"am",
"an",
"and",
"any",
"are",
"aren't",
"as",
"at",
"be",
"because",
"been",
"before",
"being",
"below",
"between",
"both",
"but",
"by",
"can't",
"cannot",
"could",
"couldn't",
"did",
"didn't",
"do",
"does",
"doesn't",
"doing",
"don't",
"down",
"during",
"each",
"few",
"for",
"from",
"further",
"had",
"hadn't",
"has",
"hasn't",
"have",
"haven't",
"having",
"he",
"he'd",
"he'll",
"he's",
"her",
"here",
"here's",
"hers",
"herself",
"him",
"himself",
"his",
"how",
"how's",
"i",
"i'd",
"i'll",
"i'm",
"i've",
"if",
"in",
"into",
"is",
"isn't",
"it",
"it's",
"its",
"itself",
"let's",
"me",
"more",
"most",
"mustn't",
"my",
"myself",
"no",
"nor",
"not",
"of",
"off",
"on",
"once",
"only",
"or",
"other",
"ought",
"our",
"ours\tourselves",
"out",
"over",
"own",
"same",
"shan't",
"she",
"she'd",
"she'll",
"she's",
"should",
"shouldn't",
"so",
"some",
"such",
"than",
"that",
"that's",
"the",
"their",
"theirs",
"them",
"themselves",
"then",
"there",
"there's",
"these",
"they",
"they'd",
"they'll",
"they're",
"they've",
"this",
"those",
"through",
"to",
"too",
"under",
"until",
"up",
"very",
"was",
"wasn't",
"we",
"we'd",
"we'll",
"we're",
"we've",
"were",
"weren't",
"what",
"what's",
"when",
"when's",
"where",
"where's",
"which",
"while",
"who",
"who's",
"whom",
"why",
"why's",
"with",
"won't",
"would",
"wouldn't",
"you",
"you'd",
"you'll",
"you're",
"you've",
"your",
"yours",
"yourself",
"yourselves",
".",
"to",
"width",
"self",
" ",
"olo",
"'re",
}
@pn.depends(token=chat.param.token)
def get_plot(token: str, token_map=token_map):
stripped_token = token.strip()
if len(stripped_token) > 2 and stripped_token not in STOP_WORDS:
token_map[stripped_token] = token_map.get(stripped_token, 0) + 1
print("adding token", "'" + stripped_token + "'")
if not token_map:
return "No data"
data = (
pd.Series(data=token_map.values(), index=token_map.keys())
.T.sort_values(ascending=False)
.head(10)
)
return data.hvplot.bar(
height=100,
title="Token Distribution (top 10)",
color="#0072b5",
)
pn.template.BootstrapTemplate(
title="🦜🔗 LangChain Streaming",
main=[chat, get_plot],
header=[
pn.Row(
pn.Spacer(),
pn.pane.Image(
"https://panel.holoviz.org/_images/logo_horizontal_dark_theme.png",
height=40,
width=200,
sizing_mode="fixed",
),
)
],
).servable()
To serve the application
pip install panel langchain hvplot -U
export OPENAI_API_KEY=...
panel serve name_of_script.py
Panel is perfect for this kind of app because it supports
- small updates (not run script top to bottom)
- async functions
- stream data via websockets
- Jupyter Notebook and server based data apps
