PyHDX v0.4.0b7

Hello everyone,
I’ve made a lot of changes to PyHDX recently and since I’m very happy with the progress so I’ve writetn an updated on the changes.
I originally posted a showcase of PyHDX (v0.3.0) now more than a year ago here and the project has come a long way since then and is now published in the journal Analytical Chemistry.
In PyHDX v0.4.0 I switched to the lumen framework for organizing the app. In this framework, users can define a dashboard app from a yaml specification. Internally, the data flow is organized by defining the Source, Filter, Transform and View classes. Here, data originates in the Source classes, gets modified by specific Filter or Transform classes and is then visualized by View classes.
This type of framework was very appealing and useful for me because it allowed me be better structure my app into a more rigid framework. As my app was getting bigger, I was losing the overview of where my data was stored and where it was processed exactly. Using distinct classes with distinct roles which can then be mixed and matched helps as lot to maintain a clear picture of your app.
However, I has some difficulty getting everything to work, mostly because lumen isnt really designed for an interactive app, but rather an interactive dashboard. It requires that all data shapes, types and fields are known a piory while in my case the app starts out empty and as the user uploads data and interacts with the app, the data is being generated and then visualized. This meant I had to make a lot of adjustments to the lumen infrastructure to get things to work, and I found myself removing a lot of parts where I didnt really understand what was going parts I didnt need. The result was a largely butchered lumen where some of the main functionality, such as defining your app from a yaml spec, wasnt even working.
Lumen light
I then decided to redo my app again and instead of basing it on lumen directly it is now lumen-inspired (or ‘lumen-light’).
I’ve kept the main components; Source, Transform (no filters), and View, but the components do not require any data when they are initialized, but instead update or redraw when the data is added. New components were added, Opts and Tools, where Opts are used to control Holoview’s graphs through .opts, in my case mostly for updating colormaps, and Tools are used to define bokeh tools such as the HoverTool
Data propagation and hashing/caching
The Source, Transform and View classes can be chained together by defining a source parameter, and request data from the class below them in the chain. They have an updated event parameter, which triggers the update() method on their dependent transforms/views, which applies the transform and triggers their updated event, thereby propagating the data towards the views.
The Transform classes optionally have widgets such that users can control the data flow. The bread and butter transform of the PyHDX app is the CrossSectionTransform, which calls .xs on the dataframe it is processing, and I’m using it very frequently in the app (about 10 instances) to allow users to choose which datasets to visualize from a typically 3-level column MultiIndex pandas dataframe. This transform generates a number of widgets depending on the multiindex depth you want to end up with and dynamically updates the options of the selectors depending on the columns in the dataframe and the selection of the higher-level selectors (See also this post here). This transform also has a redrawn event / redraw() method to generate new widgets as the input data changes. From these ~10 transforms with each 2-3 widget I would end up with roughly ~20 selectors in the GUI. However, there is a lot of overlap between these selectors to I group them by the name of the selector and create one master widget to rule them all. (So far so good but fingers crossed as I expect this to go wrong at some point). I then wind up with about 4-5 selectors (depending on which data has been generated by the user).
To make sure that not all transforms and views update when something changes at the bottom of the stack, I’m using ‘blockchain technology’  : Each
: Each Transform has a hash value calculated from its current set of parameters. This is then combined with the hash of its source to generate a new hash. When the transform updates, it checks this hash value against it stored _hash. When it is the same value, no updated is needed and updated is not triggered and the update chain is stopped. Otherwise, the _hash value is updated an an update is triggered. On top of that, you can optionally specify a global Cache object. Transforms check if their current hash in in the Cache, if so they retrieve and pass the value, otherwise they store the value. Currently Cache is either just a dict or a combination of a dict and a pd.HDFStore for larger intermediate values.
The HDF cache hasnt been tested extensively yet, but the hashing by itself already sped up my app tremendously because previously everything was updating when something changed.
Views
For the views I’m using either hvplot or holoviews. All plots use a Pipe stream and are implemented as DynamicMaps, which takes a lot of manual effort on updating the graphs off my hands, both when adding new data but also when colormaps change. The hvOverlayView allows for the combination of multiple views, which is used to generate error bars on top of a scatter graphs.
Previously I was using a custom bokeh extension implementation of the NGL protein viewer. I’ve now updated that to be a ReactiveHTML which has now allowed me to distribute the project again via PyPI and conda-force since I didnt manage to get all the bokeh building to work there. See also this post for the reactivehtml.
Yaml file and constructor
I can now define my apps similar to the lumen framework, as a yaml file. The yaml file has sections for each component; sources, transforms, opts, tools, transforms, views and then another section called modules. The modules section is just a repetition of the previous sections but allows the grouping of a set of these components when they are part of a separate pipeline, which helps keep the overview of the apps. The yaml file for the current main application can be found here
The Constructor class takes these yaml files and resolves dependencies, and creates and initializes the components. This is also where global resources, such as the Cache or a dask client are passed to the apps.
The main advantage of the yaml format for me is that it is much easier to keep an overview of whats going on in the app, and its much easier to copy paste in new components. On top of that, I’ve written a little script to use Diagrams to autogenerate a flow chart of the app. The output of this is at the bottom of this post because its rather large.
(Opts are left out here because they make a bit of a mess.)
Template and controllers
I’ve switchd the the FastGridTempalte, mostly because the GoldenTemplate was buggy in a newer version of bokeh/panel I’m using now. However I’m quite happy with it since the look is in my opinion much cleaner. I do might want to tweak the margins at some point since there is quite a bit of lost space. The only disadvantage compared to golden layout is for me the loss of flexibility, since tabs cannot be dragged around anymore.
Probably my ideal template would probably be the JupyterLab Lumino template, with some kind of sidebar as currently in the FastGridTemplate but then flexible tabs in the main area. The menu bar would also be a nice addition, where users can acces File / View / Settings etc. There is already a feature request for this here
Controls for the app are in the side bar as in the previous versions. This consists of ControlPanels in an Accordion layout. They have file input and buttons to control data analysis functions and display widgets generated by transforms (and views, not implemented) to control data flow.

The current Fast index landing page by @Marc, already looks great but needs some more awesome-panel inspiration

Future updates
Currently, there is no way of specifying a layout in the yaml file. You have to write some python code yourself at the moment and populate a template to create the final app. It not such a problem but it might be nice to have a layout system similar to how lumen does it.
Also, it like to again update how I handle async tasks. At the moment there is a loop running which checks for futures but I think it can be improved (something along the lines of what I was trying here)
There are still a lot of bugs and rough edges but the main functionality is working and so far it work very smoothly for my use cases. In the future I’m thinking of making more apps based on the same system, and if others are also interested it might be nice to release it as standalone somewhere rather than as part of PyHDX.
Any feedback or suggestions would be welcome
And here is a video of the app in action! Current version should be pip/conda installable, see GitHub
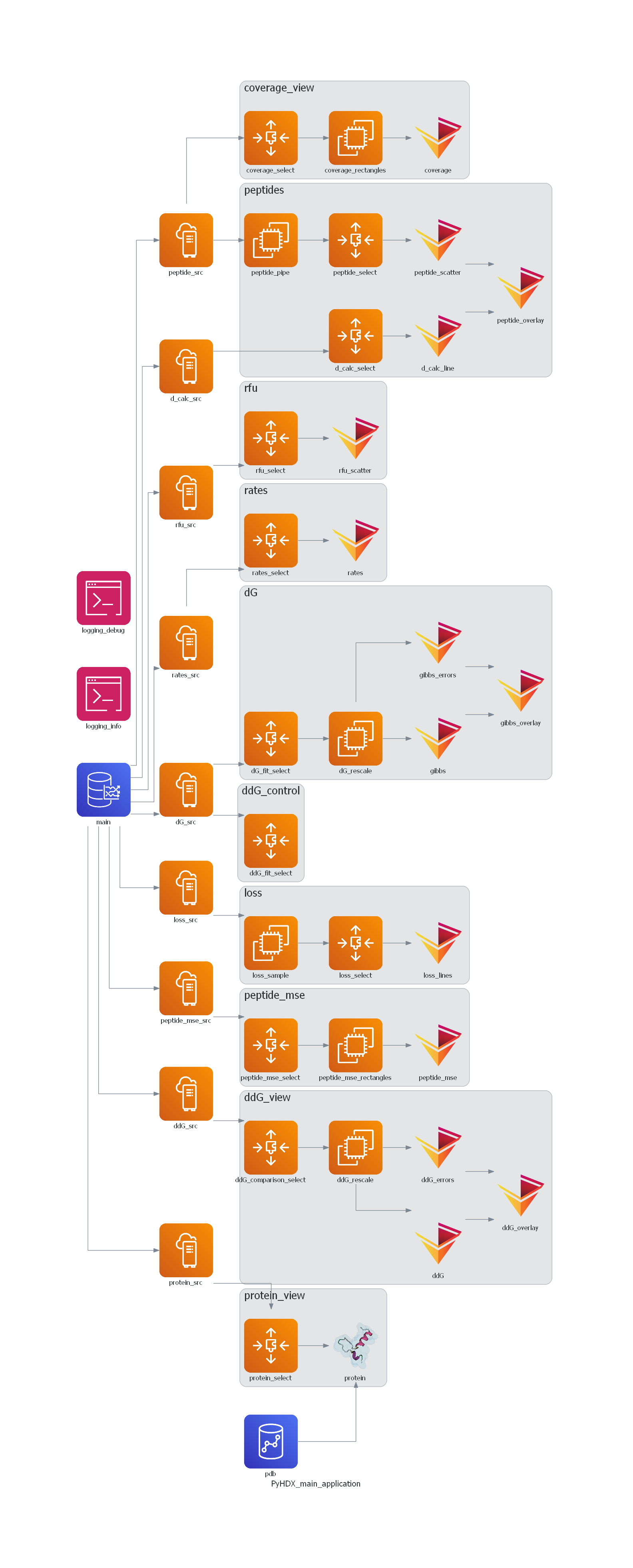
Flowchart of PyHDX sources, transforms and views (without Optss)