I’d be happy to see that in hvplot. Maybe datashade=5000 or rasterize=5000 instead of datashade=True or rasterize=True, indicating that if there are more than 5000 points visible in the current viewport then datashade it, else use raw Bokeh plotting? There are various complications like categorical plotting (supported very differently in datashader and bokeh), styling (colors, sizes, etc.). But in principle, yes.
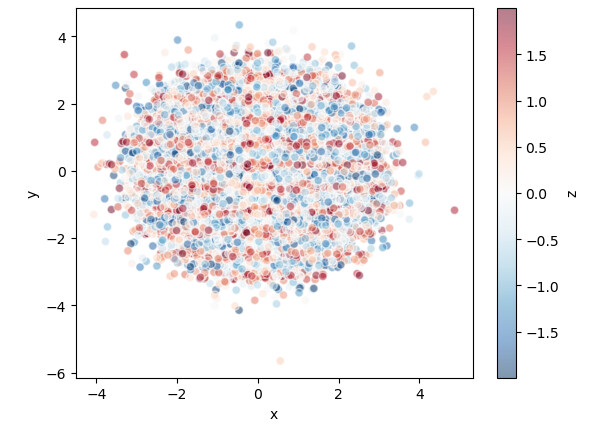
What if you have a third variable? Let’s suppose that x and y are spatial positions and you have a third variable z. I want that the aggregation shows the average z for the bins and as we zoom in, we show individual xs and ys with the respective color representing the variable z. Is that possible?
I don’t fully understand, but I’m pretty sure it’s possible if you fallback to the HoloViews level and define your callbacks manually (seen in the first post of this thread).
This might be a too naive question and sorry about that.
I am new to holoviz world and most of my experience is with matplotlib.
As I am more of a xarray person than pandas, here is my example:
import hvplot.xarray
import xarray as xr
import numpy as np
n = 100000
x = np.random.randn(n)
y = np.random.randn(n)
z = np.sin(7 * np.pi * x * x / y.std()) + np.sin(3 * np.pi * y / y.std())
# create an xarray dataset
ds = xr.Dataset(dict(x = ("obs", x), y = ("obs", y), z = ("obs", z))).set_coords(["x", "y"])
This creates a Dataset that has only one variable z with a single dimension obs and two coordinates x and y. What I usually do is:
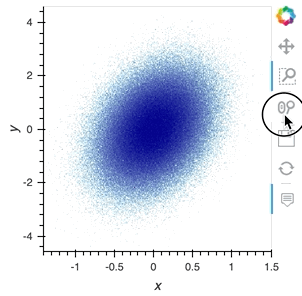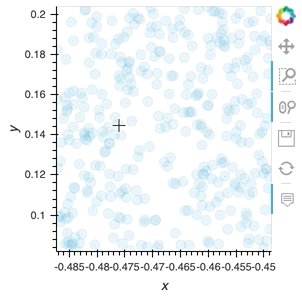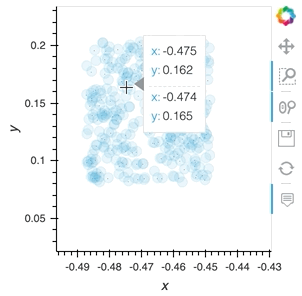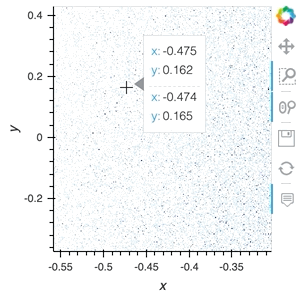
But what I want to do is to plot this using hvplot and datashader. The plot will show average z values for x and y bins and if I zoom in, it will change the bins to smaller sizes, highlighting the smaller-scale features. If I zoom “too much”, it will show separate points as you showed in the original post. Is there an easy way to do that?
It is being some days I’ve been reading the docs and despite I think these are wonderful packages, they are many and I have not seen an example like that. This is very useful for spatial data science and I can see many benefits of doing that, specially if the data is somehow lazily loaded into the memory depending on the zoom etc.
If we can come up with an example for this, I promise to organize that and add it to the gallery.
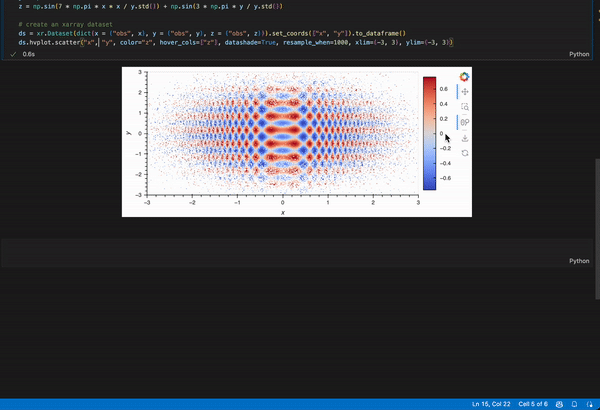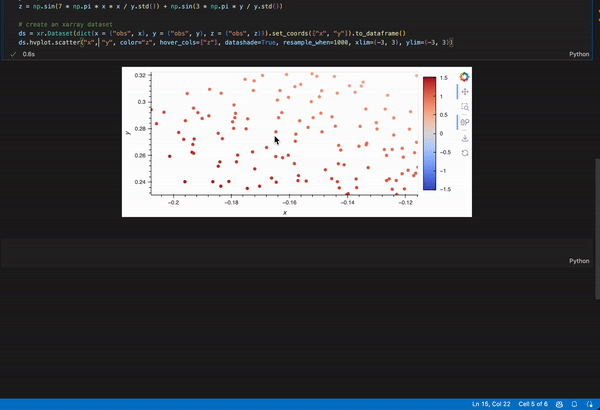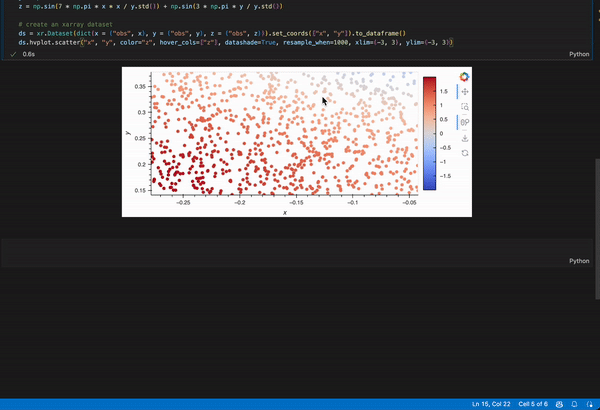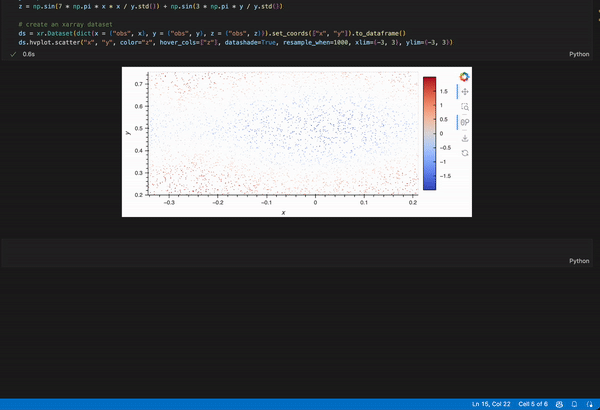
Maybe this? I converted it to a pandas dataframe because hvplot.pandas works better when the dims are 1D while hvplot.xarray works better when dims > 1D
import hvplot.pandas
import xarray as xr
import numpy as np
n = 100000
x = np.random.randn(n)
y = np.random.randn(n)
z = np.sin(7 * np.pi * x * x / y.std()) + np.sin(3 * np.pi * y / y.std())
# create an xarray dataset
ds = xr.Dataset(dict(x = ("obs", x), y = ("obs", y), z = ("obs", z))).set_coords(["x", "y"]).to_dataframe()
ds.hvplot.scatter("x", "y", color="z", hover_cols=["z"], datashade=True, resample_when=1000, xlim=(-3, 3), ylim=(-3, 3))
(To get hover, you can use rasterize=True instead of datashade)